Gehört zu: Physik
Siehe auch: Kosmologie, Tensoren, Lineare Algebra, Metrik, Allgemeine Relativitätstheorie, Quantenfeldtheorie, Schwarzes Loch
Benutzt: WordPress-Plugin Latex, Grafiken von Github, Grafiken von Wikipedia
Stand: 08.12.2024 (Vierer-Vektor, Minkowski-Metrik ausführlicher, Weltlinie, Eigenzeit, Loedel, Lorentz-Faktor, Penrose)
Überschneidungen mit: Relativitätstheorie
Was ist mit “Relativität” gemeint?
Der Begriff der “Relativität” von physikalischen Vorgängen dreht sich darum, dass ein und dieselbe Beobachtung von verschiedenen Beobachtern in verschiedenen Koordinatensystemen gemacht wird. Bei den oben genannten “physikalischen Vorgängen” handelt es sich um die Messung physikalischer Größen wie:
- Zeit
- Ort
- Geschwindigkeit
- Impuls
- Beschleunigung
- Kinetischen Energie
- Elektromagnetische Kaft
- Maxwell-Gleichungen
- …
Dabei könnten zwei Beobachter immer zu übereinstimmenden Ergebnissen kommen (so etwas nennt man dann “invariant”) oder es ergeben sich manchmal unterschiedliche Ergebnisse (“variant”). Im letzteren Fall kommt es also darauf an, welcher Beobachter diese Messung gemacht hat. Somit sind die Ergebnisse also “relativ” zu einem bestimmten Beobachter zu sehen.
Im Falle einer solchen Relativität möchte man die Messergebnisse zwischen Beobachtern formelmäßig “transformieren” können.
Dafür betrachten wir zunächstmal den einfachen Fall, dass sich die Beobachter, gleichförmig und gradlinig zu einander bewegen, also ohne Beschleunigung. Solche Beobachter bzw. deren Koordinatensysteme (Ort und Zeit) nennen wir “Inertialsysteme“.
Ein Beobachter beobachtet Ereignisse, denen er jeweils Ort und Zeit zuordnet.
Raum-Zeit-Diagramm
Solche Ereignisse kann man sich als Punkte in einem sog. Raum-Zeit-Diagramm veranschaulichen, wo die auf der einen Achse die drei Raum-Dimensionen x, y, z auf eine Dimension vereinfacht werden: x. Es bleibt als zweite Achse die Darstellung der Zeit, wobei es sich später als elegant erweisen wird, statt der “echten” Zeit das Produkt aus Lichtgeschwindigkeit und der Zeit, also c · t abzutragen.
Ein Minkowski-Diagramm ist eine ganz einfache grafische Darstellung, nämlich ein rechtwinkliges zweidimensionales Koordinatensystem mit einer Zeitachse und einer Raumachse (also der dreidimensionale Raum auf eine Dimension vereinfacht). Ein Punkt im Minkowski-Diagram wird auch Ereignis genannt, denn der Punkt beschreibt Ort und Zeit. Die Bewegung eines Punktes ist eine Linie im Raum-Zeit-Diagramm und wird seine Weltlinie genannt.
Punkte, die sich gleichförmig und gradlinig bewegen, haben dann als Weltlinie eine Gerade im Raum-Zeit-Diagramm.
Abbildung 1: Minkowski-Diagramm: Weltlinie eines Photons (Github: Minkowski_Diagram_Photon.svg)

Weltlinie eines Photons
Die Weltlinien von Teilchen mit konstanter Geschwindigkeit sind Geraden im Minkowski-Diagramm. Üblicherweise wählt man die Einheiten auf den Achsen so, dass die Weltlinien von Licht (Photonen) eine Steigung von 45 Grad haben.
Mit so einem Raum-Zeit-Diagramm stellen wir also einen 2-dimensionalen Vektorraum dar und suchen nach Transformationen, die Koordinaten eines Punktes (Ereigniss genannt) von einem Koordinatensystem in ein anderes transformieren. Da es sich bei den Koordinatensystemen um Intertialsystem handeln soll, könnten wir vermuten, dass die Transformationen auch ganz einfache sind z.B. Linerare Transformationen, die dann als Matrix dargestellt werden könnten.
Relativität bei Galileo
Bei Galileo (1564-1642) sind die die physikalischen Gesetze, speziell die Bewegungsgleichungen, identisch in allen Inertialsystemen. Es gibt kein bevorzugtes System, was etwa “in Ruhe” wäre. Jede Bewegung muss relativ zu einem Bezugspunkt gemessen werden.
Speziell für Geschwindigkeiten gilt nach Galileo das auch intuitiv einleuchtende “Additionsgesetz” d.h. wenn ein Beobachter in seinem System ein Objekt mit der Geschwindigkeit v1 misst, dann wird ein anderer Beobachter, der sich relativ zum ersten Beobachter mit der Geschwindigkeit v bewegt, die Geschwindigkeit desselben Objekts zu v2 = v1 + v messen. Wobei da noch die Richtungen berücksichtigt werden müssen, also: \( \vec{v_2} = \vec{v_1} + \vec{v} \)
Auch die Lichtgeschwindigkeit wäre in unterschiedlichen Inertialsystemen unterschiedlich.
Die Galilieo-Transformationsgleichungen wären demnach:
\( \tilde{t} = t \\ \tilde{x} = -v \cdot t + x \\ \)
Was als Galileo-Transformationsmatrix ergibt:
\( F = \left[ \begin{array}{rr} 1 & 0 \\ -v & 1 \\ \end{array} \right] \\ B = \left[ \begin{array}{rr} 1 & 0 \\ v & 1 \\ \end{array} \right] \)
Wobei F (=foreward) und B (=backward) wieder die Identität ergeben.
Youtube Video eigenchris 103d: https://youtu.be/ndjiLM5L-1s
Abbildung 2: Galilio-Transformation (Github: Gallileo.svg)

Gallileo/Newton-Transformation (blau -> rot)
Bei der Koordinatentransformation nach Gallileo/Newton verschiebt sich “nur” die x-Achse, die Zeit (t) ist in jedem bewegten Inertialsystem gleich. Deswegen würde jede Geschwindigkeit (also auch die Lichtgeschwindigkeit) verändert.
Lorentz & Co.
Die sog. Lorentz-Transformationen entstanden nach 1892 um zunächst die damals vorherrschende Äthertheorie in Einklang mit den Ergebnissen des Michelson-Morley-Experiments zu bringen. (Albert A. Michelson 1881 in Potsdam). Die Lorentz-Transformationen wurden erst 1905 von Heny Poicaré (1854-1912) so formuliert, wie wir sie heute kennen:
\( c \cdot \tilde{t} = \gamma (ct – \beta x) \\ \tilde{x} = \gamma ( -\beta c t + x) \)
wobei \( \beta = \frac{v}{c} \) und \( \gamma = \frac{1}{\sqrt{1-\beta^2}} \)
Wobei diese Faktoren so bestimmt sind, dass die Lichtgeschwindigkeit in allen Intertialsystemen gleich ist.
Als Lorentz-Transformationsmatrix ergibt sich:
\( F = \gamma \left[ \begin{array}{rr} 1 & -\beta \\ -\beta & 1 \\ \end{array} \right] \\ B = \gamma \left[ \begin{array}{rr} 1 & +\beta \\ +\beta & 1 \\ \end{array} \right] \)
Youtube Video eigenchris 104b: https://youtu.be/240YGZmV1b0
Abblidung 3: Lorentz-Transformation (Github: Lorentz.svg)

Lorentz-Transformation (blau -> rot)
Bei der Lorentz-Transformation werden beide Achsen in Richtung auf die Diagonale gedreht. Dadurch werden die ursprünglichen Quadrate zu Rhomben und die Lichtgeschwindigkeit beibt gleich (die Diagonale). Damit bleibt die Skalierung (also die Achsenteilungen) bei der Lozenz-Transformation so, dass die Flächen der Rhomben gleich den Flächen der ursprünglichen Quadrate sind. Für diese Skalierung sorgt der sog. Lorentz-Faktor γ (siehe oben).
Wenn man in so einem Minkowski-Diagramm zwei Intertialsysteme darstellen will, ist das eine rechtwinklig (chartesisch) und die Achsen des anderen sind gemäß Lorentz-Transformation schief dazu – das stört bei Manchen das ästetische Empfinden. Deshalb greift man in so einem Fall auch manchmal zu einer Variante des Minkowsiki-Diagramms, dem Loedel-Minkowsik-Diagramm (nach Ernesto Palumbo Loedel 1901-1962).
Auch der Begriff der Gleichzeitigkeit wird relativ (https://en.wikipedia.org/wiki/Relativity_of_simultaneity)
Abbildung 4: Gleichzeitigkeit (Wikipedia: https://en.wikipedia.org/wiki/Relativity_of_simultaneity#/media/File:Relativity_of_Simultaneity_Animation.gif)
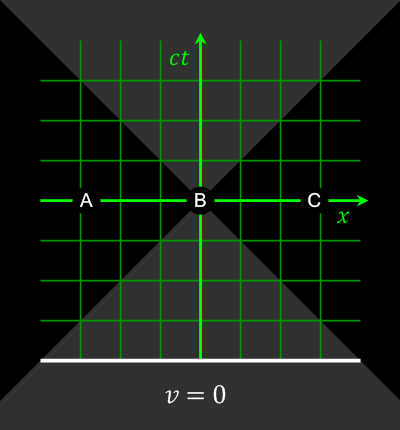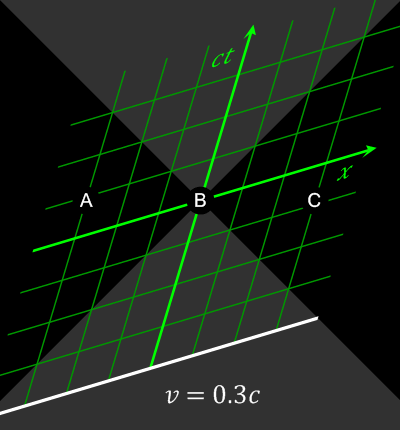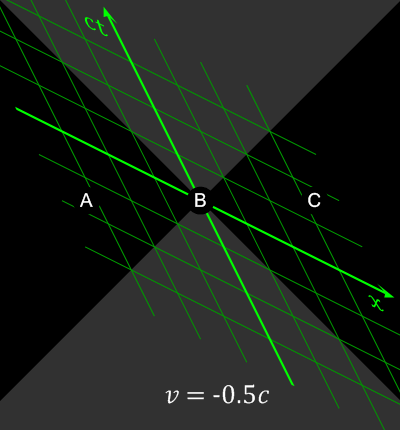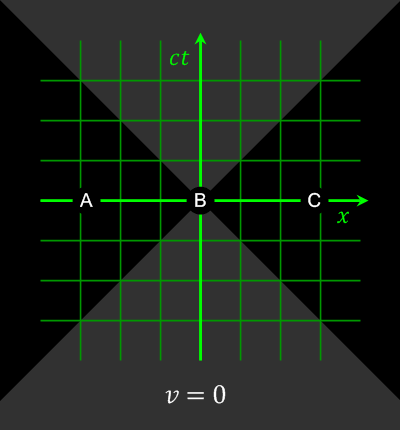
Bei Ereignissen, die raumartig (s.u.) getrennt sind (|x| > ct) kann durch eine Lorentz-Transformation die Gleichzeitigkeit und damit die Kausalität relativiert werden.
SRT Einsteins Spezielle Relativitätstheorie
Dazu habe ich einen eigenen Blog-Artikel geschrieben: Spezielle Relativitätstheorie
SRT Minkowski-Raum – Minkowski-Metrik – Linienelement
Hermann Minkowski (1864-1909) war Mathematiker und lehrte an den Universitäten Bonn, Königsberg, Zürich und hatte schließlich einen Lehrstuhl in Göttingen. In Zürich war er einer der Lehrer von Albert Einstein.
Auf Minkowski geht die Idee zurück, die Welt (wie Lorenztranformation und Spezielle Relativitätstheorie) als einen nicht-euklidischen vierdimensionalen Raum zu verstehen. Wobei er mit anschaulichen Bildern (grafischen Darstellungen) anstatt mit schwerer verständlichen Formeln arbeitete.
Zwei Begriffe kommen sofort bei “Minkowski” ins Gespräch:
- Minkowski-Raum
- Minkowski-Diagramm
Der Minkowski-Raum ist eine “größere Geschichte”: Ein vierdimensionaler Raum mit einer speziellen Metrik, denn in einem Raum möchte man ja Abstände zweier Punkte messen, Länge von Vektoren, Winkel und Flächen bestimmen. Eine solche Metrik kann man beispielsweise durch ein Skalarprodukt von Vektoren definieren.
Eine einfache Definition der Metrik im Minkowski-Raum ist gegeben durch (“Linienelement”):
ds² = c² dt² – (dx² + dy² + dz²)
Soetwas schreiben die Oberspezialisten gern als einen Tensor, auch “metrischer Tensor” genannt: \( ds^2 = g_{\mu \nu} dx^{\mu} dx^{\nu}\) (bei einem Tensor wird “implizit” summiert.)
Wenn man unser Universum als Minkowski-Raum verstehen wollte, mit einer durch das Linienelement
ds² = c² dt² – (dx² + dy² + dz²)
definierten Metrik, wäre das ein “flacher” Raum, also nicht gekrümmt (so zu sagen ohne Gravitation).
In so einem Minkowski-Raum, also mit der Minkowski-Metrik, lässt sich die Spezielle Relativitätstheorie (SRT) sehr einfach grafisch darstellen.
Das Linienelement der Minkowski-Metrik
Hermann Minkowski (1864-1909) war ein deutscher Mathematiker, der zeitweise auch Einsteins Lehrer in Zürich war.
Ein Minkowski-Diagramm ist ja relativ locker definiert (s.o.). Da haben wir eben die Zeit als weitere Dimension und beschreiben damit eine Ereignis in der Raumzeit durch einen Punkt mit vier Koordinaten:
Ereignis: e = (t, x, y, z)
Von einem Minkowski-Raum spricht man, wenn man auch noch eine Metrik hat, womit dann Abstände definiert werden. Allerdings wollen wir eine Metrik, die Lorentz-invariant ist; d.h. der Abstand zweier Ereingnisse (Punkte) soll in allen Inertialsystemen, die durch Lorentz-Transformation in einander übergehen, der gleiche sein. Mit einem einfach gedachten Linienelement:
ds² = c² dt² + dx² + dy² + dz²
funktioniert das leider nicht (kann man ausrechnen).
Als sog. Minkowski-Metrik definiert man stattdessen das Linienelement:
ds² = c² dt² – (dx² + dy² + dz²)
Die dadurch definierte Metrik ist tatsächlich Lorentz-invariant (kann man ausrechnen). Formal wird diese Minkowski-Metrik definiert durch einen Metrik-Tensor, den sog. Minkowski-Tensor (siehe dort).
So eine Metrik definiert zunächsteinmal die Länge eines Vektors \( \vec{S} = ( x^1, x^2, x^3, x^4 ) \) als:
\( || \vec{S} || = \sqrt{\vec{S} \cdot \vec{S}} = \sqrt{g_{ij} x^i x^j} \)
Um den Abstand zweier Ereignisse in unserer Raumzeit s1 = (t1, x1, y1, z1) und s2 = (t2, x2, y2, z2) zu ermitteln, nehmen wir die Länge des Differenz-Vektors:
\( s^2 = || s_2 – s_1 || = c^2 (t_2 – t_1)^2 – (x_2 – x_1)^2 – (y_2 – y_1)^2 – (z_2 – z_1)^2 \)
In so einem Minkowski-Raum, also mit der Minkowski-Metrik, lässt sich die Spezielle Relativitätstheorie (SRT) demnach sehr einfach grafisch darstellen eben weil diese Metrik Lorentz-invariant ist.
Man sagt auch: Wenn man unser Universum als Minkowski-Raum verstehen wollte, mit dieser Metrik, wäre das ein “flacher” Raum, also nicht gekrümmt (so zu sagen ohne Gravitation).
Raumartig, Zeitartig, Lichtartig
Für den Abstand zweier Ereignisse können wir unterscheiden:
- \( s^2 > 0 \) : Der Abstand wird “zeitartig” genannt – die Ereignisse sind zeitartig getrennt
- \( s^2 < 0 \) : Der Abstand wird “raumartig” genannt – die Ereignisse sind raumartig getrennt
- \( s^2 = 0 \) : Der Abstand wird “lichtartig” genannt
Auf eine Raum-Dimension vereinfacht, ist der Minkowski-Abstand: \( s^2 = c^2 t^2 – x^2 \). Damit ist dann:
- Zeitartiger Abstand: \( x < ct \)
- Raumartiger Abstand: \( x > ct \)
- Lichtartiger Abstand: \( x = ct \)
Abblidung 5: Minkowski-Metrik (Github: Minkowski-02.svg)

Kurven als Weltlinie
Die Begriffe “raumartig” (space like) und “zeitartig” (time like) werden auch für Kurven im Minkowski-Diagramm verwendet.
Dabei betrachtet man infenitesimal kleine Kurvenstücke und fragt sich, ob diese als Intervall immer raumartig oder immer zeitartig sind.
Ein wichtiges Thema sind “closed timelike curves”…
Minkowski-Abstand
Man darf sich von der Optik des Minkowski-Diagramms nicht zu vereinfachten Schlüssen verführen lassen. Bei einem Minkowski-Abstand von: \( s^2 = c^2 t^2 – x^2 \) liegen beispielsweise alle Punkte (Ereignisse), die vom Koordinatenursprung den Minkowski-Abstand 1 haben, nicht auf der Kugelschale mit Radius 1, sondern die Menge (ct, x):
\( 1 = {ct}^2 – x^2 \)
Das ist eine Hyperbel im Minkowski-Diagramm. Dort liegen also alle Punkte im ursprünglichen Bezugssystem (ct,x), die eine Abstand 1 vom Koordinatenursprung haben.
Da dieser Anstand invariant ist, liegt dort also auch für jedes Lorenz-transformierte Bezugssystem (ct’, x’) der Punkt auf der transformierten Raum-Achse, der einen Abstand 1 vom Ursprung hat.
Wir müssen also immer daran denken, dass im Minkowski-Raum nicht die vom Diagramm “vorgegaukelte” Euklidische Geometrie gilt, sondern der Minkowski-Abstand.
Abbildung 6: Minkowski-Abstand (Github: hyperbel.svg)

Minkowski-Metrik
Vierer-Vektoren
Im Raum-Zeit-Diagramm ist ein Punkt ein Ereignis, beschrieben durch seinen Ort im Raum und den Zeitpunkt; man benötigt im dreidimensionalen Raum also 4 Koordinaten (siehe Koordinatensysteme). Man spricht deswegen auch von einem Vierer-Vektor:
\( \vec{S} = \left[ \begin{array}{c} c t \\\ x \\\ y \\\ z \end{array} \right] \\\)
Mit der Vektor-Basis ausgedrückt ist das:
\( \vec{S} = ct \cdot \vec{e_t} + x \cdot \vec{e_x} + y \cdot \vec{e_y} + z \cdot \vec{e_z} \\ \)
Entsprechend hätte man Vierer-Geschwindigkeit, Vierer-Impuls, Vierer-Beschleuigung etc.
In der Physik interessiert oft die Veränderung einer Größe mit der Zeit. Dazu müsten wir nach er Zeit differenzieren.
Der springende Punkt bei diesen “Vierer-Vektoren” ist aber nicht die eigentlich triviale Tatsache, dass die Vektoren vier Komponenten haben, sondern die Art und Weise, wie nach der Zeit differenziert wird. Die Zeit-Koordinate (“Koordinatenzeit”) ist ja in jedem Interialsystem eine andere, weshalb für die Differenzierung von Vierer-Vektoren nach der Zeit die sog. Eigenzeit (engl. proper time, Symbol τ) genommen wird. Wobei beim Differenzieren von dieser Vektoren genaugenommen die covariante Ableitung genommen wird.
Bei einer genaueren Definition des Begriffs “Vierer-Vektor” würde man noch die Invarianz der Vektor-Länge bei Lorenztransformationen fordern. Die Länge eines Vierer-Vektors ergibt sich dabei durch die Metrik.
Solche Vierervektoren spielen eine wichtige Rolle bei den Einsteinschen Feldgleichungen der ART.
Siehe auch: http://walter.bislins.ch/blog/index.asp?page=Bewegungsgleichung+der+Speziellen+Relativit%E4tstheorie
Eigenzeit in der Minkowski-Metrik
Als Eigenzeit (Symbol τ) eines bewegten Objekts (entlang einer beliebigen Weltlinie) bezeichnet man die Zeit, die eine “mitbewegte” Uhr zeigt. Jede Weltlinie hat eine eigene Eigenzeit.
Wir werden sehen: Die Eigenzeit ist die auf einer Weltlinie gemessene Länge in der Minkowski-Metrik und deshalb auch Lorenz-invariant.
Im Gegensatz dazu ist die Zeitkoordinate (auch Koordinatenzeit) eben eine von vier Koordinaten im verwendeten Koordinatensystem und transformiert sich, wenn wir auf ein anderes Koordinatensystem übergehen.
Für den einfachen Fall eines Objektes, dass sich geradlinig mit konstanter Geschwindigkeit \( \vec{v} \) bezüglich unseres Bezugssystems (ct, x) bewegt, ist das ganz einfach. Dann ist die Weltlinie dieses Objekts eine Gerade in unserem Koordinatensystem und wir häten die Bewegung:
\( x(t) = ||\vec{v}|| \cdot t \)
Wir können an ein solches Objekt dann ein Koordinatensystem (ct’, x’) “anheften”, was wieder ein Intertialsystem wäre. Man spricht vom “mitbewegten” System. Den Zusammenhang liefert die Lorenz-Transformation. Wenn wir jetzt einen Zeitabschnitt von \(\Delta t \) (in unserem Bezugssystem) betrachten, wäre die Frage. welche Zeit im mitbewegten Bezugssystem dann vergeht.
\( \Delta t^{\prime} = \sqrt{1-\frac{||v||^2}{c^2}} \cdot \Delta t \)
Wenn wir nun ein Objekt betrachten, dass sich nicht auf einer Geraden als Weltlinie bewegt, wäre ein mitbewegtes Bezugssystem kein Inertialsystem mehr. Die dort vergangene Zeitspanne von ta bis te, also die Eigenzeit, ergibt sich dann aufintegriert als:
\( \tau = \displaystyle\int\limits_{t_a}^{t_e} \sqrt{1-\frac{||v(t)||^2}{c^2}} \, dt \)
Diese Eigenzeit τ würde dann von allen Intertialsystemen aus gesehen gleich sein d.h. Lorenz-invariant.
Euklidische Vektoren
Im klassischen Eukidischen Raum (soll heissen ohne die SRT) haben wir es generell mit 3er-Vektoren zu tun:
Ortsvektor: \( \vec{r} = x \cdot \vec{e_x} + y \cdot \vec{e_y} + z \cdot \vec{e_z} \)
Geschwindigkeit: \( \vec{u} = \frac{d \vec{r}}{d t} \)
Impuls: \( \vec{p} = m \cdot \vec{u} \)
Beschleunigung: \( \vec{a} = \frac{d^2 \vec{r}}{d t^2} = \frac{d \vec{u}}{d t} \)
Kraft: \( \vec{f} = \frac{d \vec{p}}{d t} = m \cdot \vec{a} \)
Minkowski-Vektoren
Wenn wir das Obige nun nach SRT und in beliebigen Inertialsystemen betrachten wollen, haben wir gleich ein Problem mit den Ableitungen nach der Zeit. In jedem Inertialsystem verläuft die Zeit (auch Koordinatenzeit genannt) anders; d.h. die o.g. Größen sind nicht mehr Lorenz-invariant.
Lorenz-invariant sind zunächst:
- Die Lichtgeschwindigkeit: c
- Der Minkowski-Abstand zweier Ereignisse: \( S = c \cdot (t_2 – t_1) – (x_2 – x_1)^2 – (y_2 – y_1)^2 – (z_2 -z_1)^2 \)
Einerseits ist die Zeit eine Koordinate in der vierdimensionalen Raumzeit, andererseits können wir zeitliche Abstände zwischen zwei Ereignissen messen.
Anstelle der Zeit (Koordinatenzeit), die in allen Inertialsystem verschieden sein kann, definieren wir eine sog. Eigenzeit τ, die invariant sein soll. Danach können die das differenzieren und kämen zu invarianten Größen….
Bei den Minkowski-Vektióren (Vierervektoren) gehen wir aus vom Ortsvektor, der die Bewegung eines Massepunkts m in seiner Eigenzeit beschreibt (Weltlinie):
\( \vec{S} = ct \cdot \vec{e_t} + x \cdot \vec{e_x} + y \cdot \vec{e_y} + z \cdot \vec{e_z} \\ \)
Durch Differenzieren nach der Eigenzeit kommen wir dann zu:
Vierer-Geschwindigkeit: \( \vec{U} = \Large \frac{d\vec{S}}{d\tau} \)
Vierter-Impuls: \( \vec{P} = m \cdot \vec{U} \)
Vierer-Beschleunigung: \( \vec{A} = \Large \frac{d^2\vec{S}}{d\tau^2} = \frac{d\vec{U}}{d\tau} \)
Vierer-Kraft: \( \vec{F} = \Large \frac{d\vec{P}}{d\tau} = m \cdot \vec{A} \)
Wie differenziere ich nun nach der Eigenzeit?
Vierer-Geschwindigkeit:
\( \Large \vec{U} =\frac{d\vec{S}}{d\tau} = \frac{d}{d\tau}( ct \cdot \vec{e}_t + x \cdot \vec{e}_x + y \cdot \vec{e}_y + z \cdot \vec{e}_z ) \)
In einem Inertialsystem sind die Basisvektoren konstant; d.h. die Ableitungen auch nach τ sind Null. Damit vereinfacht sich die Produktregel und wir erhalten:
\( \Large \vec{U} = \frac{d\vec{S}}{d\tau} = c \frac{dt}{d\tau} \vec{e}_t + \frac{dx}{d\tau} \vec{e}_x + \frac{dy}{d\tau} \vec{e}_y + \frac{dz}{d\tau} \vec{e}_z \)
Penrose-Diagramme
So ein Raum-Zeit-Diagramm nach Minkowski benutzt ja eine unendliche Ebene zur Darstellung. Durch eine geeignete Koordinatentransformation können wir so eine unendliche Ebene auf eine endliche Figur abbilden…
Roger Penrose (*1931)
Tangens

