Diesen Blog-Artikel schreibe ich ausschließlich zu meiner persönlichen Dokumentation; quasi als mein elektronisches persönliches Notizbuch. Wenn es Andere nützlich finden, freue ich mich, übernehme aber keinerlei Garantie für die Richtigkeit bzw. die Fehlerfreiheit meiner Notizen. Insbesondere weise ich darauf hin, dass jeder, der diese meine Notizen nutzt, das auf eigene Gefahr tut. Wenn ich Produkteigenschaften beschreibe, sind dies ausschließlich meine persönlichen Erfahrungen als Laie mit dem einen Gerät, welches ich bekommen habe.
Mittelwert
In der Physik bestimmt man Messgrößen meist in dem man eine Messung wiederholt ausführt und dann (meist) den Mittelwert aus den Einzelmessungen nimmt.
Neben dem Mittelwert einer solchen Messreihe ist aber auch noch interessant die Streuung der Messwerte und die Anzahl der Messungen. Auf grafischen Darstellungen (Diagrammen) von Messungen wird oft zusätzlich zum Mittelwert ein sog. Fehlerbalken gezeigt, der mit einem oberen und einem unteren Wert etwas über die “Genauigkeit” aussagen soll.
Streuung
Der Streubereich der Einzelwerte zeigt an, wie genau man dem Mittelwert eigentlich trauen kann. Falls die Einzelwerte normalverteilt sind, nimmt man gerne die sog. Standardabweichung (Symbol σ) als Maß für die Streuung.
Üblich als Bemessung von Fehlerbalken damit sind ±1 σ oder auch ±2 σ.
Bei einer Normalverteilung sind im Intervall ±1 σ etwa 68% und im Intervall ±2 σ etwa 95% der Werte.
Auf jeden Fall sollte man bei der Beschriftung eines Diagramms auch angeben, welche Art von Fehlerbalken dargestellt sind.
Anzahl der Messungen
Die Anzahl der Einzelmessungen einer Messreihe wird auch als Stichprobengröße (Symbol n) bezeichnet.
Bei einer sehr kleinen Stichprobengröße wird man einem errechneten Mittelwert nicht so vertrauen; bei einer größeren Anzahl Einzelmessungen wird das Vertrauen in den Mittelwert steigen. Das wird man auch durch entsprechend größere oder kleinere Fehlerbalken anzeigen wollen. Solche Fehlerbalken können verschieden berechnet werden: Standardfehler (Standard Error of the Mean SEM) oder Konfidenzintervall (CI).
Auf jeden Fall sollte man bei der Beschriftung eines Diagramms auch angeben, welche Art von Fehlerbalken dargestellt sind.
Fehlerbalken in der Praxis
In der Astronomie und der Astrophysik werden üblicherweise als Fehlerbalkentyp die ±2 σ Bemessung verwendet.
Für Konfidenzintervalle nimmt man gerne ein Konfidenzniveau von 95%.
In der Teilchenphysik (z.B. Higgs-Teilchen in CERN) gilt 5σ als sog. Goldstandard um die extrem hohe statistische Signifikanz zu beschreiben, die für eine offizielle Entdeckung erforderlich ist.
Systematische Fehler
Zusätzlich zu den oben behandelten statistischen Fehlern von Messungen, kann auch die Messmethode selbst noch systematische Fehler enthalten; diese können nur durch eine kritische Analyse des Messverfahrens selbst zu Tage gefördert werden, wobei auch Verfahren der Fehlerfortpflanzung Anwendung finden werden.
Gerne werden auch statistischer Fehlerbalken und systematischer Fehler zusammengezogen als Quadratwurzel aus der Summe der quadrierten Fehler.
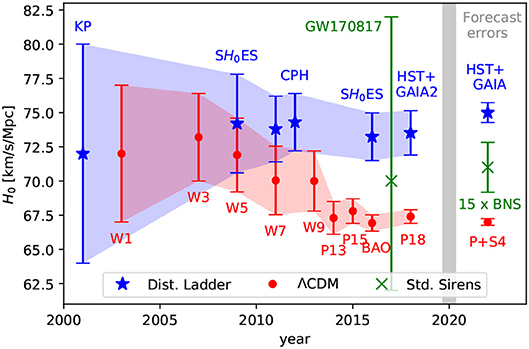
Beispiel: Der Hubble-Parameter
Die Messungen des Hubble-Parameters sind ein klassisches Beispiel für Fehlerbalken-Darstellungen. Im untenstehenden Diagramm werden zwei unterschiedliche Messverfahren gegenübergestellt und wie sich die Fehlerbalken im Lauf der Jahre verändert haben.
Wenn sich die Bereiche nicht überlappen, ist der Verdacht naheliegend, dass ein signifikanter Unterschied zwischen den Messreihen besteht…
Die Standardabweichung ist ein Maß für die Streuung der Einzelwerte der Messreihe um den ihren Mittelwert.
Diese Standardabweichung (Standard Deviation) der Messreihe berechnen wir so:
\( \Large S = \sqrt{\frac{ \sum\limits_{i=1}^{i=n} {(x_i – \bar{x}})^2 }{n-1}}\\\)
Der Standard Error of the Mean (SEM) dagegen, beziffert die Genauigkeit des Mittelwerts der Messreihe in Bezug auf den “wahren” Wert; eigentlich durch mehrmalige Wiederholung der ganzen Messreihe. Dieser SEM errechnet sich ganz einfach zu:
\( SEM = \Large\frac{\sigma}{\sqrt{n}} \\\)
Wobei σ die Standardabweichug der Grundgesamtheit ist, die wir aber nicht wirklich kennen. In der Praxis verwendet man als Schätzwert für σ ganz einfach die Standardabweichung der einen Messreihe, womit man erhält:
Diesen Blog-Artikel schreibe ich ausschließlich zu meiner persönlichen Dokumentation; quasi als mein elektronisches persönliches Notizbuch. Wenn es Andere nützlich finden, freue ich mich, übernehme aber keinerlei Garantie für die Richtigkeit bzw. die Fehlerfreiheit meiner Notizen. Insbesondere weise ich darauf hin, dass jeder, der diese meine Notizen nutzt, das auf eigene Gefahr tut. Wenn ich Produkteigenschaften beschreibe, sind dies ausschließlich meine persönlichen Erfahrungen als Laie mit dem einen Gerät, welches ich bekommen habe.
Mannigfaltigkeiten braucht man beispielsweise, wenn man Gegenstände behandeln will, die nicht so flach wie die Euklidische Ebene, sondern “gekrümmt” sind.
Das klassische Beispiel, mit dem Karl Friedrich Gauss (1777-1855) zu kämpfen hatte, ist die Erdoberfläche, die er als zweidimensionale Mannigfaltigkeit behandeln wollte.
Gauss war der Doktorvater von Bernhard Riemann (1826-1866), der den Begriff der Mannigfaltigkeiten dann später einführte.
Topologischer Raum
Bevor wir Mannigfaltigkeiten behandeln, müssen wir uns noch kurz erinnern, wie das mit Topologischen Räumen war.
\( \emptyset \in \mathbb{O} \land M \in \mathbb{O} \)
Die Elemente von \(\mathbb{O} \) nennt man “offene” Mengen.
Wenn wir einen Metrischen Raum haben, induziert die Metrik auf natürliche Weise eine Topologie.
Wir können aber einiges auch schon ohne Metrik, nur mit Topologie, definieren z.B.:
Stetigkeit
Intuitiv bedeutet “stetig” dass bei kleinen Änderungen im Argument, der Funktionswert sich auch nur “entsprechend” wenig ändert.
Für Topologische Räume können wir das formal so definieren:
Eine Abbildung f von einem Topologischen Raum A in einen anderen topologischen Raum B
\( f: A \to B \)
heißt stetig, wenn die Urbilder offener Mengen wieder offene Mengen sind.
Homöomorphismus
Ein Homöomorphismus ist eine bijektive, stetige Abbildung, deren Umkehrabbildung ebenfalls stetig ist.
Wenn es zwischen zwei Topologischen Räumen einen Homöomorphismus gibt, nennt man die Räume homöomorph, was umgangssprachlich meint “sieht so aus wie”.
Grenzwert (Limes)
In einem Topologischen Raum M können wir den Begriff “Grenzwert” definieren, ohne eine Metrik zu benutzen.
Wir sagen eine Folge von Teilmengen \(\left(x_i\right)_{ i \in N} \) konvergiert gegen einen Grenzwert x ∈ M, geschrieben:
\( x = \lim\limits_{i \to \infty} x_i \)
genau dann, wenn es für jede (noch so kleine) offene Menge U mit x ∈ U ein io ∈ N gibt, sodass xi ∈ U für alle i ≥ i0.
Umgebungen
Eine Teilmenge U von M heisst Umgebung eines Punktes x aus M, genau dann wenn es eine offene Menge O gibt, sodass:
\( x \in O \subset U \\ \)
Hausdoffraum
Ein Topologischer Raum M heißt Hausdorff Raum, wenn es für je zwei verschiedene Punkte x und y aus M jeweils offene Umgebungen Ux und Uy gibt, die diese Punkte enthalten und sich nicht überschneiden.
Dies nennt man auch das “Trennungsaxiom”.
In einem Hausdorff Raum ist damit der Limes einer Folge eindeutig.
Abzählbarkeitsaxiom
xyz
Topologische Mannigfaltigkeit
Die Grundidee ist, dass eine solche Mannigfaltigkeit lokal Euklidisch ist; d.h. eine Euklidische Topologie hat.
Eine (topologische) Mannigfaltigkeit ist ein Topologischer Raum M, der lokal Euklidisch ist.
Das bedeutet, dass jeder Punkt x ∈ M eine Umgebung hat, die homöomorph zu einer offenen Teilmenge eines Euklidischen Raums wie \( \mathbb{R}, \mathbb{R}^2, \mathbb{R}^3,\ldots\) ist.
Wir möchten für solche Topologischen Mannigfaltigkeiten einen Dimensionsbegriff haben. Deswegen definieren wir noch etwas anders:
Eine n-dimensionale (topologische) Mannigfaltigkeit ist ein Topologischer Raum, der lokal homöomorph zu \( \mathbb{R}^n \) ist.
Dann will man noch einige “pathologische” Fälle ausschließen. Deswegen fügen wir zur Definition noch zwei spezielle Forderungen hinzu und definieren nun:
Das erste Abzählbarkeitsaxiom muss erfüllt sein.
Der Raum ist ein Haussdorffraum.
Der Raum ist lokal homöomorph zu \( \mathbb{R}^n \)
Neben dem Begriff der “Topologischen Mannigfaltigkeit” gibt es noch den Begriff der “Differenzierbaren Mannigfaltigkeit” das brauchen wir später bei den Lie-Gruppen und der Quantenphysik.
Karten
Eine Karte ist ein Paar (U,φ) wobei U eine offene Teilmenge der Mannigfaltigkeit M ist und \( \phi: U \to V \subset \mathbb{R}^n \) ein Homöomorphismus.
Der Homöomorphismus φ stellt für U lokale Koordinatensysteme bereit, wodurch man den Teilraum U ⊂ M wie einen Teilraum von \( \mathbb{R}^n \) behandeln kann.
Atlas
Ein Atlas einer Mannigfaltigkeit M ist nun eine Menge (Familie) von Karten \( A = (U_i, \phi_i) \), die die Mannigfaltigkeit M vollständig abdeckt; also \( \cup \, U_i = M \)
Dabei kann es Überlappungsbereiche zwischen zwei Karten geben, etwa \( U_\alpha \cap U_\beta \neq \emptyset \). In so einem Überlappungsbereich können wir durch die Abbildung \( \phi_\alpha \cdot {\phi_\beta}^{-1} \) einen sog. Kartenwechsel vornehmen.
Differenzierbare Mannigfaltigkeiten
Eine differenzierbare Mannigfaltigkeit ist ein mathematisches Objekt, das lokal wie ein euklidischer Raum aussieht und auf dem Differenzieren möglich ist.
Zunächst muss das ein n-dimensionaler Topologischer Raum (s.o.) sein.
Zusätzlich sollen die Übergänge zwischen den lokalen Darstellungen (Kartenwechsel) beliebig oft differenzierbar sein.
Diesen Blog-Artikel schreibe ich ausschließlich zu meiner persönlichen Dokumentation; quasi als mein elektronisches persönliches Notizbuch. Wenn es Andere nützlich finden, freue ich mich, übernehme aber kleinerlei Garantie für die Richtigkeit bzw. die Fehlerfreiheit meiner Notizen. Insbesondere weise ich darauf hin, dass jeder, der diese meine Notizen benutzt, das auf eigene Gefahr tut. Wenn Podukteigenschaften beschrieben werden, sind dies ausschließlich meine persönlichen Erfahrungen als Laie mit dem einen Gerät, welches ich bekommen habe.
Die die Anfänge der Wahrscheinlichkeitstheorie stammen wohl aus der Spieltheorie z.B. Würfelspiele etc.
In der klassische Definition hat man:
Eine Menge von Elementarereignissen Ω, die alle gleich wahrscheinlich sein sollen
Ein Zufallsexperiment bei dem ein Element x ∈ Ω gezogen wird.
Man definiert eine Teilmenge A ⊂ Ω.
Dann fragt man sich, mit welcher Wahrscheinlichkeit das gezogene Element in der Teilmenge A liegen wird.
Anzahl “günstige” Fälle / Anzahl aller möglichen Fälle
Als Formel:
\( P(A) = \Large\frac{|A|}{|Ω|} \\ \)
Das ist die sog. Laplace-Wahrscheinlichkeit.
Solange die Menge Ω endlich ist funktioniert das ja bestens.
Man nennt diese Sichtweise auch die “frequentistische”. Da geht es also um relative Häufigkeiten und wiederholbare Versuche, die langfristig sich der “wahren” Wahrscheinlichkeit annähern.
Axiomatische Wahrscheinlichkeitstheorie
Andrei Nikolajewitsch Kolmogorow (1903-1987) hat die Wahrscheinlichkeitsrechnung axiomatisch aufgebaut.
Sei Ω eine beliebige nicht leere Menge und P eine Funktion (Abbildung), die Teilmengen von Ω eine reelle Zahl zuordnet.
Eine Teilmenge von A ⊂ Ω nennen wir auch ein “Ereignis” und die zugeordnete Zahl P(A) die “Wahrscheinlichkeit” des Ereignisses A.
Für alle Ereignisse A ist P(A) ≥ 0
Die Wahrscheinlichkeit des sicheren Ereignisses Ω ist P(Ω) = 1
Wenn wir zwei Ereignisse A und B betrachten, die “unvereinbar” sind; soll heissen A ∩ B = Ø, dann gilt:
P(A ∪ B) = P(A) + P(B)
Problematisch wird das, wenn die Grundmenge Ω überabzählbar ist. Dann kann man nicht jeder Teilmenge A ⊂ Ω eine reelle Zahl P(A) zuordnen, so dass die obigen Axiome erfüllt sind. Der Definitionsbereich der Funktion P muss dann etwas “trickreicher” definiert werden, was man mit Hilfe der Maßtheorie hinbekommt (Stichwort: σ-Algebra).
Bedingte Wahrscheinlichkeit
Die Wahrscheinlichkeit für das Eintreten von A unter der Bedingung, dass das Eintreten von B bereits bekannt ist schreibt man als: P(A|B).
Aufgepasst: die Ereignisse A und B können zeitlich in beliebiger Reihenfolge eintreten. Ein Kausalzusammenhang ist erst recht nicht gemeint.
Wahrscheinlichkeit nach Thomas Bayes
Man nennt diese bisherigen Betrachtungen auch die “frequentistisch”. Da geht es also um relative Häufigkeiten und wiederholbare Versuche, die langfristig sich der “wahren” Wahrscheinlichkeit annähern.
Wir beginnen mal mit der “Bedingten Wahrscheinlichkeit” von oben. Man kann die Formel dafür auch anders schreiben:
\( P(A|B) = \Large \frac{P(B|A) P(A)}{P(B)} \)
Dieses wird auch genannt “Satz von Bayes“.
Wenn ein Ereignis nicht wiederholbar ist, versagt die frequentistisch Definition von Wahrscheinlichkeit.
Beispiele:
“Die Inflation wird im nächten Jahr mehr als 2% sein”
“Wie wahrscheinlich ist ein Wahlsieg des ehemaligen Präsidenten?”
“Wie hoch ist morgen die Regenwahrscheinlichkeit?”
Hier wird der Begriff “wahrscheinlich” umgangssprachlich verwendet – so in etwa in dem Sinne:
Wahrscheinlichkeit ist ein Maß für die Sicherheit der (persönlichen) Einschätzung eines Sachverhalts.
Wahrscheinlichkeiten in diesem Sinne werden auch vergleichend (“komperativ”) gebraucht: “Die Wahrscheinlichkeit für Regen morgen ist höher als für Regen übermorgen”.
Insofern könnte man eine so gemeinte Wahrscheinlichkeit auch sinnvoll durch eine Zahl zwischen Null und Eins ausdrücken. Man muss dieses o.g. “Maß” also irgendwie quantifizieren.
Für so eine Quantifizierung der Bayesschen Wahrscheinlichkeit gibt es zwei Ansätze.
Ansatz 1: de Finetti
Die Idee ist, dass man Gewissheit durch eine Art Wette quantifizieren kann.
Zu jedem Ereignis A, dem ich eine Wahrscheinlichkeitszahl zuordnen will mache ist ein Los, für das der Käufer einen “Gewinn” von 1 Euro von mir bekommt, wenn das Ereignis A eintrifft. Die Frage ist, zu welchem Preis ich so ein Los verkaufen würde. Dieser Preis, den ich festlege ist so etwas wie die von mir (subjektiv) eingeschätzte Sicherheit/Wahrscheinlichkeit mit der ich glaube, dass das Ereignis eintreten wird.
Ich muss zu diesem Preis (oder höher) verkaufen, wenn ein Käufer das anbietet; ich muss zu diesem (oder einem niedrigeren) Preis selber (zurück)kaufen, wenn ein Verkäufer das von mir verlangt.
Ansatz 2: Erweiterung der klassische Logik
Nachwievor arbeiten wir mit Aussagen die entweder (ganz) wahr oder (ganz) falsch sind, wir wissen es nur nicht genau. Daher ordnen wir solchen Aussagen Plausibilitäten zu (auf Grund von Tatsachen, die wir kennen).
Im Prinzip betrachten wir nicht allein Aussagen, sondern Kombinationen von Aussagen und Informationsständen und schreiben als Plausibilität von A bei einem Informationsstand I:
(A,I) ∈ [0,1]
Wobei das eine reelle Zahl zwischen o und 1 sein soll und bei gleichem A und gleichem I auch (A,I) immer gleich sein soll (Plausibilitäsroboter – also nicht subjektiv).
Das ganze soll nicht der Aussagenlogik widersprechen, was wir in einfachen Axiomen hinschreiben könnten.
Diesen Blog-Artikel schreibe ich ausschließlich zu meiner persönlichen Dokumentation; quasi als mein elektronisches persönliches Notizbuch. Wenn es Andere nützlich finden, freue ich mich, übernehme aber kleinerlei Garantie für die Richtigkeit bzw. die Fehlerfreiheit meiner Notizen. Insbesondere weise ich darauf hin, dass jeder, der diese meine Notizen nutzt, das auf eigene Gefahr tut. Wenn Podukteigenschaften beschrieben werden, sind dies ausschließlich meine persönlichen Erfahrungen als Laie mit dem einen Gerät, welches ich bekommen habe.
Mit Hilfe der Variationsrechnung versucht man Minima zu finden.
Beispiele:
Der kürzeste Weg zwischen zwei Punkten
Die kürzeste Zeit einer Bewegung (Fermat’sches Prinzip)
Die kleinste Oberfläche eines Volumens
Die kleinste “Wirkung” in einem physikalischen System (s.u.)
…
Im Gegensatz zur Schul-Mathematik suchen wir jetzt nicht einen Punkt, bei dem eine Funktion ein Minimum hat, sondern einen Pfad (also eine Funktion) bei der ein “Funktional” (Funktion von Funktionen) ein Minimum hat.
Die Euler-Lagrange-Gleichung
Wir haben eine Funktion entlang eines Pfades. Wobei so ein Pfad definiert sei durch eine Funktion y = y(x) zwischen den Stellen x1 und x2. Wir können eine Funktion F entlang eines Pfades “aufsummieren” d.h. integrieren. Wir suchen nun zu einer gegebenen Funktion F denjenigen Pfad, bei dem dieser Integralwert ein Mininimum wird.
\( S = \int\limits_{x_1}^{x_2} F(x, y, y^\prime) \, dx = Minimum \\\)
Um das Minimum dieses Integralwertes über alle Pfade zu finden, “differenziert” man S nach dem Pfad und schreibt δS=0; d.h. eine infinitesimal kleine Änderung im Pfad soll nur eine infinitesimal kleine Änderung in S bewirken. Man nennt einen solchen Pfad auch “stationär”.
Leonard Euler (1707-1783) entwickelte dazu die “Variationsrechnung”. Sein Trick war, “kleine Änderungen” eines Pfades mathematisch zu beschreiben und einen Methode zu finden, danach zu differenzieren.
Nach längerem Rechnen (auch mit Integration by Parts) bekommt man als Lösung der Minimum-Aufgabe die berühmte Euler-Lagrange-Gleichung,
Diesen Blog-Artikel schreibe ich ausschließlich zu meiner persönlichen Dokumentation; quasi als mein elektronisches persönliches Notizbuch. Wenn es Andere nützlich finden, freue ich mich, übernehme aber kleinerlei Garantie für die Richtigkeit bzw. die Fehlerfreiheit meiner Notizen. Insbesondere weise ich darauf hin, dass jeder, der diese meine Notizen nutzt, das auf eigene Gefahr tut. Wenn Podukteigenschaften beschrieben werden, sind dies ausschließlich meine persönlichen Erfahrungen als Laie mit dem einen Gerät, welches ich bekommen habe.
Die Integralrechnung bildet zusammen mit der Differentialrechnung, das was die Engländer und Amerikaner “Calculus” nennen. Bei uns sagt man eher “Infinitesimalrechnung”. Erfunden haben sollen das Newton und Leibnitz unabhängig von einander.
Die Grundlagen haben wir in der Schul-Mathematik gelernt.
Allgemeines
Es gibt ein bestimmtes Integral und ein unbestimmtes Integral.
Das unbestimmte Integral einer Funktion ist einfach die Umkehroperation zum Differenzieren. Man sucht eine sog. Stammfunktion, die differenziert die ursprüngliche Funktion ergibt. Zur Stammfunktion kommt dann immer eine beliebige Integrationskonstante dazu.
Das bestimmte Integral geht von einer Untergrenze zu einer Obergrenze. Da hebt sich eine Integrationskonstante immer weg. Man verbildlicht sich das gerne als Fläche unter einer Kurve.
Wichtige Regeln
Das Integrieren einer Funktion ist im allgemeinen schwieriger als Differenzieren, weil man ja eine Stammfunktion sucht, die…
Neben den vielen einfachen Regeln in der Integralrechnung gibt es eine, die ich aus der Schule so nicht wirklich kannte: “Integration by Parts“.
Integration by Parts (Partielle Integration)
Wenn man ein Integral lösen will, was trotz der üblichen Bemühungen (z.B. algebraisch Vereinfachen, Substituieren,…) widerspenstig ist, hilft es manchmal es so umzuschreiben, dass dann die Lösung klappt.
\( \Large \int u \, dv = u \cdot v \, \, – \int v \, du \)
Wir bekommen statt eines “unschönen” Integrals nun ein anderes Integral; das würde Sinn machen, wenn das neue Integral einfacher zu lösen wäre.
Man muss dazu geschickt wählen, was u sein soll und was dv sein soll.
Beispiel:
\( \Large \int x \cdot e^x \, dx = ? \)
Wir versuchen es mit: \( u = x \). Dann muss \( dv = e^x \, dx \) sein.
Um die Formel anzuwenden, brauchen wir dazu du und v.
\(du\) bekommen wir durch Differenzieren von \( u \): \( du = dx \)
\(v\) bekommen wir durch Integrieren von \( dv \): \( v = e^x \)
Das setzen wir nun in die Formel ein:
\(\Large \int x \cdot e^x \, dx = x \cdot e^x – \int e^x \, dx\\\)
Das neue Integral können wir leicht lösen und bekommen also:
\(\Large \int x \cdot e^x \, dx = x \cdot e^x – e^x + c\)
Tipps zur “Integration by Parts”
Man kann einen “schwierigen” Integranden ja verschieden in Faktoren (u und dv) aufbrechen.
Wenn ein Versuch nicht zum Ziel führt, kann man einen neuen Versuch machen etc.
Generell sagt man, dass man denjenigen Faktor als “u” wählen sollte, der beim Differenzieren einfacher wird wobei der andere Faktor “dv” dann beim Integrieren keine Schwierigkeiten machen sollte.
Ein Körper ist eine Menge K mit zwei (zweistelligen) Verknüpfungen, die meist Addition und Multiplikation genannt werden. Für die folgende Axiome gelten:
(1) Bezüglich der Addition genannten Verknüpfung soll die Menge eine abelsche Gruppe sein – das Neutrale Element schreiben wir als: 0.
(2) Bezüglich der Multiplikation genannten Verknüpfung soll die Menge K ohne das Element 0 eine abelsche Gruppe sein – das Neutrale Element schreiben wir als: 1.
Es gibt also zu jedem Element \( k \in K \text{ aber } k \neq 0 \) ein Inverses, geschrieben \( k^{-1} \); also: \( k \cdot k^{-1} = 1 \).
(3) Distributivgesetz: \( a \cdot (b + c) = (a \cdot b) + (a \cdot c) \)
Beispiele
Die Menge der Ganzen Zahlen \( \mathbb{Z} \) bildet keinen Körper, sondern (nur) einen Ring.
Die Menge der Rationalen Zahlen \( \mathbb{Q} \) bildet einen Körper.
Die Menge der Reellen Zahlen \( \mathbb{R} \) bildet einen Körper.
Die Menge der Komplexen Zahlen \( \mathbb{C} \) bildet einen Körper.
Ordnungsrelation auf \( \mathbb{Q} \)
Im Körper der Rationalen Zahlen \( \mathbb{Q} \) können wir eine Ordnungsrelation definieren durch:
\( \Large \frac{a}{b} \ge \frac{c}{d} \normalsize \text{ genau dann, wenn: } a d \ge c b \text{ in } \mathbb{Z} \)
Norm in \( \mathbb{Q} \)
Für ein Element \( a \in \mathbb{Q} \) können wir eine Norm |a| definieren:
\( |a| = a \text{ wenn } a \geq 0, -a \text{ wenn } a \lt 0 \\ \)
Diese Norm ist abgeschlossen in \( \mathbb{Q} \), denn es gilt:
\( a \in \mathbb{Q} \Rightarrow -a \in \mathbb{Q} \\\)
Die Norm ist also so etwas wie der Betrag oder auch die Länge.
Da \( \mathbb{Q} \) ein Körper ist, kann man die Norm auch über das Produkt definieren:
\( |a| = \sqrt{a \cdot a} \)
Metrik in \( \mathbb{Q} \)
Mit Hilfe der Norm können wir eine Metrik \( d: \mathbb{Q} \times \mathbb{Q} \to \mathbb{R} \) definieren:
d(a,b) = |a – b|
Man spricht auch davon dass a und b einen “Abstand” von d(a,b) haben.
Folge und Grenzwert
Als Folge in einem Körper K wir bezeichnet eine Abbildung:
\( \mathbb{N} \to K \)
Meist geschrieben als: a1, a2, a3,… mit ai ∈ K.
Cauchy-Folge
Eine Folge ai heisst Cauchy-Folge wenn für jedes (noch so kleine) ε > 0 eine natürliche Zahl Nε exisistiert, sodass:
\( | a_n – a_m | < ε \text{ für alle } n,m \in \mathbb{N} \text{ mit } n, m > N_\epsilon \\\)
Die Elemente einer Cauchy-Folge rücken also beliebig dicht aneinander. Wo bei “dicht” meint, dass der Abstand beliebig klein wird.
Grenzwert einer Folge
Eine Folge ai hat einen Grenzwert g ∈ K wenn für jedes ε > 0 eine natürlche Zahl Nε exisistiert, sodass:
\( | a_n – g | < ε \text{ für alle } n \in \mathbb{N} \text{ mit } n \gt N_\epsilon\\\)
Die Elemente der Folge kommen dem Grenzwert beliebig nahe. Man sagt auch, dass die Folge konvergiert gegen den Grenzwert.
Falls so ein Grenzwert g ∈ K exisitiert, schreiben wir:
\( g = \lim \limits_{i \to \infty} {a_i} \\\)
Vollständigkeit
Wenn jede Cauchy-Folge von Elementen aus K auch konvergiert (und zwar gegen einen Grenzwert, der ebenfalls in K liegt), sagt man dass K vollständig sei.
Diese Eigenschaft wird später für Hilberträume (Vektorraum) wichtig werden.
Vektorraum
Jeder Körper K ist auch ein Vektorraum über K (also über sich selbst).
Bei meiner Beschäftigung mit der Gruppentheorie bin ich auf das klassische Thema Äquivalenzklassen gestoßen.
Eine Äquivalenzrelation in der Mathematik ist ersteinmal eine “Relation”. Dann soll diese Relation inetwa die Eigenschaften haben, die wir von der klassischen Äquivalenz her kennen: Gleichheit oder Ungleichheit.
Allgemein: Was ist eine Relation?
Auf einer Menge M können wir eine Relation R einfach definieren als eine Teilmenge der geordneten Paare. Also
\( R \subseteq M \times M \\\)
So eine Relation wird dann Äquivalenzrelation genannt, wenn sie noch zusätzlich drei wichtige von der Gleichheitsrelation bekannten Eingenschaften besitzt: reflexiv, symmetrisch, transitiv.
Reflexiv: \( (a,a) \in R \text{ für alle } a \in M \\\)
Symmetrisch: \( \text{Wenn } (a,b) \in R \text{ dann ist auch } (b,a) \in R \\\)
Transitiv: \( \text{Wenn } (a,b) \in R \text{ und } (b,c) \in R \text{ dann ist auch } (a,c) \in R \\\)
Wenn es aus dem Kontext klar ist, welche Relation gemeint ist, schreibt man auch einfach: \( a \sim b\text{ für } (a,b) \in R \)
Äquivalenzklassen
Wenn ich eine Äquivalenzrelation R auf einer Menge M habe, kann ich damit zu jedem Element m ∈ M eine Teilmenge von M definieren:
\( [m]_R = \{ x \in M \,|\, (m,x) \in R \} \\\)
Diese Teilmenge nennt man Äquivalenzklasse von m (bezüglich der Relation R auf M). Wenn man zwei Äquvalenzklassen betrachtet, sind diese entweder identisch oder disjunkt.
Da jedes Element der Menge M auch in einer (genau einer) Äquivalenzklasse vorkommt, bilden die Äquivalenzklassen also eine (disjunkte) Partition von M.
Faktor-Mengen
Wenn wir die Menge der Äquivalenzklassen betrachten ist aus unserer ursprünglichen Relation dort die Gleichheitsrelation geworden.
Die Menge der Äquivalenzklassen zu einer Relation R über M bezeichnet man auch als Faktor-Menge oder Quotienten-Menge und schreibt:
\( M/R = \{ [m]_R \,|\, m \in M \} \\ \)
Beispiele von Konstruktionen mit Hilfe von Faktormengen
Generell kann man mit diesem Mechanismus viele interessante mathematische Gebilde konstruieren…
Die Menge der ganzen Zahlen: \( \mathbb{Z} = (\mathbb{N}^2 \times \mathbb{N}^2) / R_1 \)
Wobei die Relation R1 definiert wird als: (n1, n2) ∼ (m1, m2) genau dann wenn n2 + m1 = m2 + n1
Die Menge der rationalen Zahlen: \( \mathbb{Q} = (\mathbb{Z}^2 \times \mathbb{Z}^2) / R_2 \)
Wobei die Relation R2 definiert wir als: (n1, n2) ∼ (m1, m2) genau dann wenn n2 · m1 = m2 · n1
Äquivalenzklassen in der Gruppentheorie
In der Gruppentheorie kann man mittels einer Untergruppe H einer Gruppe G sog. “Cosets” zu jedem Element g aus G bilden:
\( gN = \{ x \in G \, | \, \exists h \in H \text{ with } x = g \cdot h \} \\\)
Diese Cosets (deutsch: Nebenmengen) bilden eine disjunkte Überdeckung der Gruppe G.
Ich kann mir auch ganz einfach eine Äquivalenzrelation R definieren, die diese gleichen Nebenmengen als Äquivalenzklassen erzeugt. Dazu muss ich nur definieren, wann zwei Elemente x und y aus G zueingabder in Relation stehen sollen…
Ich versuche es einmal mit: \( R = \{ (x,y) \, | \, \exists h \in H : h\cdot x = h \cdot y \} \\ \)
Ist das wirklich eine Äquivalenzrelation (1) und erzeugt sie tatsächlich die gewünschen Äquivalenzklassen (2)?
Ad (1): Als Äquivalenzrelation wäre zu überprüfen:
Reflexivität; d.h. ist (x,x) immer in R? Offensichtlich stimmt das.
Symmetrie: d.h. wenn (x,y) in R liegt, liegt dann auch (y,x) in R?
Wenn demnach (x,y) in R liegt, existiert ein h in H sodass hx = hy. Dann ist mit dem gleichen h aus H auch hy = hx. Also ist R symmetrisch.
Transitivität:
Wenn (x.y) und (y,z) in R liegen, so heisst das: Es gibt ein h1 und ein h2 in H sodass gilt: h1 x = h1 y und h2 y = h2 z.
Man könnte es mit h = h1 h2 versuchen, was bei einer kommutativen (abelschen) Gruppe funktionieren würde…
Diesen Blog-Artikel schreibe ich ausschließlich zu meiner persönlichen Dokumentation; quasi als mein elektronisches persönliches Notizbuch. Wenn es Andere nützlich finden, freue ich mich, übernehme aber kleinerlei Garantie für die Richtigkeit bzw. die Fehlerfreiheit meiner Notizen. Insbesondere weise ich darauf hin, dass jeder, der diese meine Notizen nutzt, das auf eigene Gefahr tut. Wenn ich Podukteigenschaften beschreibe, sind dies ausschließlich meine persönlichen Erfahrungen als Laie mit dem einen Gerät, welches ich bekommen habe.
Eine Gruppe in der Mathematik ist eine Menge mit einer “inneren” Verküpfung (die man gerne mit dem Symbol “+” schreibt) und die bestimmten, unten aufgeführten Axiomen genügt.
Die Verknüpfung
Die Menge bezeichnen wir mal mit M und nehmen dann zwei Elemente aus dieser Menge:
\( a \in M \) und \( b \in M \)
Dann soll die Verknüpfung (geschieben als +) von a und b wieder in der Menge M liegen:
\( a + b \in M \)
Die Axiome
Damit das ganze dann eine Gruppe ist, müssen folgende Axiome gelten:
Assoziativgesetz:
\( (a + b) + c = a + (b + c) \\ \)
Existenz eines “neutralen Elements” e, sodass:
\( \exists e \in M \space \forall a \in M: a + e = a \\\)
Existenz eines inversen Elements zu jedem Element der Gruppe:
\( \forall a \in M \space \exists b \in M : a + b = e \\ \)
Beispiel 1: Die ganzen Zahlen
Die Menge der ganzen Zahlen \(\mathbb{Z}\) mit der Addition als Verknüpfung bildet eine Gruppe.
Beispiel 2: Die Kleinsche Vierergruppe
Die Kleinsche Vierergruppe (nach Felix Klein 1849-1925) besteht aus vier Elementen, wobei jedes Element mit sich selbst invers ist.
Die Menge schreiben wir als:
V = {e, a, b, c}
Die Verknüpfung definieren wir über eine Verknüpfungstafel (auch Cayley Table genannt):
e
a
b
c
e
e
a
b
c
a
a
e
c
b
b
b
c
e
a
c
c
b
a
e
Wie man leicht sieht, werden mit der so definierten Verknüpfung die Gruppenaxiome erfüllt.
Beispiel 3: Die komplexen Zahlen auf dem Einheitskreis
In der komplexen Zahlenebene \(\mathbb{C}\) ist er Einheitskreis einfach die Teilmenge S der komplexen Zahlen, die wir definieren als:
Als Verknüpfung auf dieser Menge nehmen wir die Multiplikation der komplexen Zahlen; geometrisch können wir uns das als Drehungen vorstellen.
Damit wird das Ganze eine Gruppe.
Symmetrien und Drehungen
Gruppen kann man also ganz axiomatisch Definieren, wie oben; in der Praxis sind die Elemente einer Gruppe typischerweise die Symmetrien eines Objekts.
Ganz allgemein bilden die Symmetrien eines “Objekts” eine Gruppe. Eine speziell Art von Symmetrien sind Drehungen. Wir betrachten solche “Objekte” als Teilmengen eines Vetorraums; wobei wir uns auf Vektorräume über dem Körper der Reellen Zahlen oder dem Körper der Komplexen Zahlen konzentrieren. Weiterhin sollte die Dimesion des Vektorraums angegeben werden.
Die Leute, die sich mit den verschiedenen Arten von “Drehungsgruppen” als Spezialgebiet beschäftigen, bezeichnen die Gruppe der komplexen Zahlen auf dem Einheitskreis auch gerne als U(1); wobei die “1” bedeuten soll, dass wir nur eine Drehachse haben und das “U” steht für “unitär”, was man gerne zu einer Verknüpfung (Abbildung) sagt, wenn die Länge gleich bleibt (“längentreu”) – allerdings müsste man dann den Begriff “Länge” noch definieren.
Solche Gruppen, die aus Drehungen bestehen, spielen später im Standardmodell der Elementarteilchenphysik eine wichtige Rolle. Wobei eine Drehung auch als sog. “kontinuierliche Symmetrie” bezeichnet wird.
Da solche Drehungen ja “kontinuierlich” (im Gegensatz zu Spiegelungen) um auch beliebig kleine Winkel stattfinden können, kommt man damit auch in das Gebiet der Differentialgeometrie und letztlich zum Begriff der Lie-Gruppen (s.u.).
Für Drehungen in der reellen Ebene kann man eine reelle Dreh-Matrix nehmen:
Vergleiche hierzu auch das YouTube-Video von Josef Gassner: https://www.youtube.com/watch?v=zFhjF6sfY4o
Nur für Mathematiker:
Drehungen im n-dimensionalen komplexen Raum sind lineare Abbildungen und damit als eine spezielle Art von nxn-Matrizen darstellbar.
\(U(n) = \{ U \in \text{ nxn Matrix } | \space U^\dagger U = I \} \)
Die nxn-Matrizen werden auch “General Linear Group” genannt und man schreibt sie als: \(GL(n,\mathbb{C}) \), wobei man zusätzlich fordert: det(U)>0 damit jede Matrix U invertierbar ist und so \(GL(n,\mathbb{C}) \) eine Gruppe ist.
Direktes Produkt von Gruppen
Wenn wir zwei Gruppen G und H haben, können wir das sog. “Direkte Produkt” dieser zwei Gruppen bilden, indem wir von den Mengen das cartesische Produkt \(G \times H\) nehmen und eine Verknüpfung auf diesem cartesischen Produkt komponentenweise definieren.
Wenn wir die Verknüpfungen mit dem Zeichen “+” schreiben, wäre das also:
\((g_1,h_1) + (g_2,h_2) = (g_1+g_2,h_1+h_2) \text{ wobei } g_1, g_2 \in G \text{ und } h_1,h_2 \in H\\\)
Wobei uns klar ist, dass das Symbol “+” hier für drei verschiedene Verknüpfungen benutzt wird.
Die Menge \(G \times H\) ausgestattet mit der so definierten Verknüpfung bezeichnet man als “Direktes Produkt” der Gruppen G und H und schreibt das als \(G \oplus H\).
Lie-Gruppen
Sophus Lie (1842-1899) beschäftigte sich mit besonderen Gruppen, man nun Lie-Gruppen nennt. Es gibt auch den Begriff der Lie-Algebren, die aber etwas anderes sind.
Eine Lie-Gruppe ist eine mathematische Struktur, die sowohl eine Gruppe als auch eine differenzierbaren Mannigfaltigkeit ist.
Bei einer Funktion von \(\mathbb{R} \to \mathbb{R} \) ist ja klar, was eine Ableitung (Differentialquotient) ist: Anschaulich die Änderungsrate des Funktionswerts an einer bestimmten Stelle…
Wenn der Definitionsbereich einer Funktion nicht mehr \(\mathbb{R}\) sondern \(\mathbb{R}^3\) ist, nennt man eine solche Funktion auch ein “Skalarfeld”, weil durch die Funktion jedem Punkt im Raum \(\mathbb{R}^3\) ein skalarer Wert zugeordnet wird (Beispiel: Temperatur). Eine “Änderungsrate” einer solchen Funktion wäre dann ja von der Richtung abhängig, in die ich gehe; also muss so eine “Änderungsrate” ein Vektor werden. So eine “Änderungsrate” eines Skalarfeldes nennt man dann den “Gradienten” s.u.
Sei also \( \Phi \) eine Funktion \(\Phi: \mathbb{R}^3 \to \mathbb{R} \) dann ist der Gradient von \( \Phi \) :
Generell definiert man auf einem Vektorraum dann besondere Abbildungen, sog. Differentialoperatoren. Man benutzt dazu die Koordinatenschreibweise. Wir nehmen hier immer die klassischen Cartesischen Koordinaten. Wenn man andere Koordinatensystem hat, sehen die Formeln dann etwas anders aus.
Wir nehmen als Definitionsbereich für unsere “Felder” den Vektorraum \(\mathbb{R}^3\). dann haben wir partielle Ableitungen nach den drei Koordinaten: x, y und z und man definiert als sog. Nabla-Operator:
Im einfachen Fall, wenn unser Definitionsbereich nur ein Vektorraum der Dimension 1 ist (\(\mathbb{R}^1\)), ist der Gradient einfach die erste Ableitung.
Kraftfeld und Gradient
In einem konservativen Kraftfeld F(r) kann man als Skalar ein Potential V(r) definieren, sodass die Kraft der Gradient den Potentials wird:
\( \vec{F}(r) = \nabla V(r) \)
Elektrisches Feld und Divergenz
Ein Elektrisches Feld wird durch eine ruhende elektrische Ladung erzeugt.
Ein Elektrisches Feld ist ein Vektorfeld, das man üblicherweise \( \vec{E} \) schreibt.
Feldstärke – Feldlinien – xyz
Für das von einer Elektrischen Ladung Q erzeugte E-Feld \( \vec{E} \) gilt:
\( \nabla \cdot \vec{E} = 4 \pi Q \\\)
Da die Elektrische Ladung Q sozusagen das Elektrische Feld erzeugt, nennt man es auch die Quelle des E-Feldes…
Magnetisches Feld
Ein Magnetisches Feld wird durch bewegte elektrische Ladungen erzeugt.
Ein Magnetisches Feld ist ein Vektorfeld, das man üblicherweise \( \vec{B} \) schreibt.
Für ein Magnetisches Feld gilt:
\( \nabla \cdot \vec{B} = 0 \\\)
D.h. es gibt keine Quelle und alle Feldlinien sind geschlossen…
Eine der Voraussetzungen zum Verständnis vieler Dinge (z.B. in der Allgemeinen Relativitätstheorie und der Quantenmechanik) sind sog. Vektorräume und Tensoren.
Ein Vektorraum kann axiomatisch wie folgt definiert werden:
Axiom 1: Vektorräume verfügen über eine Operation, die Vektor-Addition (Vektor plus Vektor ergibt einen Vektor) genannt wird und eine kommutative (abelsche) Gruppe bildet. Axiom 2: Jeder Vektorraum muss einen Körper haben, dessen Elemente Skalare genannt werden. Mit solchen Skalaren können wir die Vektoren mutiplizieren (“skalieren“); d.h. Skalar mal Vektor ergibt Vektor.
Man spricht dann von einem Vektorraum “über” einem Körper K seiner Skalaren oder kurz von einem K-Vektorraum.
Solche Axiome ergeben eine abstrakte Definition von Eigenschaften; die Frage ist allerdings, ob es tatsächlich “Gebilde” gibt, die diese Axiome erfüllen. Tatsächlich gibt es viele “Gebilde”, die die Vektorraum-Axiome erfüllen: d.h. die tatsächlich Vektorräume sind. Beispiele für Vektorräume sind u.a.:
Ein \(\mathbb{R}^n \) wird mit den naheliegenden Operationen Vektorraum über \(\mathbb{R}\)
Ein \(\mathbb{C}^n \) wird mit den naheliegenden Operationen Vektorraum über \(\mathbb{C}\)
Die Menge der Funktionen auf \(\mathbb{R}\) kann auch als Vektorraum ausgestattet werden…
Ein abstrakter Vektorraum kann auch veranschaulicht werden:
Physik: Der Physiker stellt sich Vektoren gern als “Pfeile” vor, die also eine Richtung und eine Länge haben, also eher “geometrisch“.
Computer: Der Computer-Mensch stellt sich Vektoren eher als Liste von Komponenten vor (Vektor = Liste) – wozu man aber ersteinmal ein System von Basis-Vektoren (nicht: Koordinatensystem) haben muss.
Mathematik: Der abstrakte Mathematiker sagt, Vektoren sind einfach “etwas”, was man addieren kann (Gruppe) und was man mit “Skalaren” skalieren kann – fertig, einfach ein paar Axiome und das war’s.
Linearkombinationen
Mit einem Satz von Vektoren kann man eine sog. Linearkombination bilden, beispielsweise:
Zu einem Satz Vektoren \( \vec{g_1}, \vec{g_2}, …, \vec{g_n} \) wäre eine Linearkombination etwa:
Wobei wir jeden Vektor \( \vec{g_i} \)mit einem Skalar \( a_i \) multiplizieren und die Summe bilden.
Vektorbasis und Dimension
Wenn ich mit einem Satz von Vektoren jeden Vektor des Vektorraums durch eine Linearkombination darstellen kann, sagt man “der Satz von Vektoren spannt den Vektorraum auf”. Ist so ein Satz von Vektoren minimal und die Darstellung eines Vektors durch eine Linearkombination damit eindeutig, so nennt man den Satz von Vektoren eine Vektorbasis.
Soweit ist dies eine axiomatische Definition von Eigenschaften, welche eine Vektorbasis erfüllen muss. Die Frage ist allerdings, für einen bestimmten Vektorraum, ob dort auch tatsächlich eine solche Vektorbasis exsitiert.
Die Antwort lautet: Jeder Vektorraum hat (mindestens) eine Vektorbasis.
Falls ein Vektorraum mehrere Vektorbasen hat sind alle diese Vektorbasen gleich mächtig. Die Kardinalzahl (Mächtigkeit) heist Dimension des Vektorraums, geschrieben dim(V).
Eine Einheitsbasis (normal basis) ist eine Basis, bei der alle Basisvektoren die Länge 1 haben (“auf die Länge 1 normiert sind”).
Was die Länge eines Vektors sein könnte, kommt weiter unten.
Beispiel:
Der euklidische Vektorraum: \(\mathbb{R}^n\)
Dort haben wir z.B. eine Vektorbasis: \( \vec{e}_i = (\delta_{i}^j) \)
Wobei das Kronecker-Delta bekanntlich definiert ist als:
Damit ich mit einem Vektor so schön herumrechnen kann, ist es enorm praktisch, den Vektor durch “seine” Komponenten darzustellen. Solche “Komponenten” beziehen sich immer auf eine sog. Vektorbasis.
Den Satz von Skalaren mit dem ein Vektor bezüglich einer Vektorbasis als Linearkobination eindeutig dargestellt werden kann nennt man auch die Komponenten des Vektors. Man schreibt also:
Dabei sind also die ai die Komponenten des Vektors a bezüglich des gewählten Basisvektorsystems. Der Begriff von Koordinaten in einem Koordinatensystem unterscheidet sich von diesem Begriff der Komponenten bezüglich eines Basisvektorsystems.
Der Physiker möchte die Formeln noch kompakter aufschreiben und führt eine impliziete Summenkonvention ein (nach Einstein). Danach verwenden wir Indizes teilweise unten (klassisch) und auch teilweise oben (neu). Wenn ein gleicher Index oben und unten auftaucht, soll darüber summiert werden (ohne dass man es expliziet schreiben muss). Also in unserem Fall:
\( \vec{a} = a^i \vec{g_i} \)
Man nennt Größen mit einem Index unten “kovariant” und mit einem Index oben “kontravariant” – was man damit eigentlich sagen will werden wir später erfahren.
Komponentenschreibweise
Unsere Rechenregeln für Vektoren kann man nun auch einfach in Komponentenschreibweise ausdrücken:
Geschrieben werden Vektoren meist als eine Liste ihrer Komponenten, aber nicht waagerecht, sondern senkrecht angeordnet (bei waagerechter Anordnung denkt man eher an einen Punkt im Raum).
\( \Large \vec{v} = \left( \begin{array}{c} x \\\ y \\\ z \end{array}\right) \)
oder auch in eckigen Klammern:
\( \Large \vec{v} = \left[ \begin{array}{c} x \\\ y \\\ z \end{array} \right] \)
Wenn ich Vektoren als Liste von Komponenten schreiben will, muss ich ersteinmal ein Basisvektorsystem haben.
Vektoren, und das ist wichtig, exisitieren auch ohne Basisvektorsysteme, also einfach geometrisch im Raum. Unabhängig von einem Basisvektorsystem hat jeder Vektor eine Länge und eine Richtung. Dies sind also sog. “Invarianten”; d.h. bei Änderung des Basisvektorsystems ändern sich diese Eigenschaften nicht.
Also: Vektoren ansich sind invariant gegenüber einem Wechsel des Basisvektorsystems. Aber die Vektorkomponenten verändern sich beim Wechsel des Basisvektorsystems, sind wie man sagt “variant“. Wie Vektorkomponenten bei Wechsel des Basisvektorsystems hin- und hergerechnet werden können, behandeln wir weiter unten. So ein Vektor ist damit der Sonderfall eines Tensors, nämlich ein Tensor vom Rang 1.
Lineare Abbildung (Lineare Transformation)
Wir betrachten zwei Vektorräume V und W über dem gleichen Körper K habe. Eine Abbildung \( f: V \to W \) nennt man auch Transformation. Wenn V=W ist spricht man auch von einer Operation auf V und nennt f einen Operator.
Lineare Transformationen sind Transformationen, bei denen Geraden Geraden bleiben und der Null-Punkt (Origin) unverändert bleibt.
Anschaulich gesagt, bleiben Parallelen parallel und die Koordinatengitter gleichmäßig unterteilt (was immer auch Parallelen und Koordinatengitter genau sein mögen). Man kann das auch abstrakt durch Formeln ausdrücken:
Eine solche Abbildung f von einem Vektorraum V in einen Vektorraum W (beide über dem gleichen Körper K)
\( f: V \to W \\ \)
wird “linear” genannt, wenn sie additiv und homogen ist; d.h. wenn für alle \( \vec{v} \in V \text{ und alle } \vec{w} \in V \) gilt:
homogen: \( f(a \vec{v}) = a f(\vec{v}) \) (hierfür brauchen wir den gleichen Körper K)
allgemein also: \(f(a \vec{x} + b \vec{y}) = a f(\vec{x}) + b f(\vec{y}) \)
General Linear Group
Zu einem Vektorraum V über K können wir die Menge der linearen invertierbaren Abbildungen \( f: V \to V \) betrachten. Diese nennen wir: General Linear Group und schreiben GL(V). Wenn man die allgemeine Verknüpfung von Abbildungen als Guppenverknüpfung nimmt, ist GL(V) tatsächlich eine Gruppe.
Die GL(V) ist ein schönes Beispiel für eine nicht abelsche (nicht kommutative) Gruppe.
Siehe hierzu auch das schöne Youtube-Video von Josef Gassner:
In der Quantenmechanik (Quantenphysik) sind die Untergruppen von GL(V) sehr interessant.
Dualer Raum
Zu einem Vektorraum V über dem Körper K definieren wir eine “Dualen Vektorraum” V* wie folgt:
Als Menge V* nehmen wir alle linearen Abbildungen \( f: V \to K \)
Als Vektor-Addition in V* definieren wir: \( (f+g)(v) = f(v) + g(v) \)
Und als Skalar-Multiplikation in V* nehmen wir: \( (\lambda \cdot f)(v) = \lambda \cdot f(v) \)
Bilinerarform
Hier geht es um zwei Variable (zwei = bi); also eine Abbildung:
\( f: V \times V \to K \\\) (mit V Vektorraum über dem Körper K)
So eine Abbildung heisst “bilinear“, wenn sie “in beiden Variablen” linear ist, was heisst:
Ein Vektorraum verfügt nicht notwendig über ein Skalarprodukt. Auf einem Vektorraum kann ein Skalarprodukt definiert sein (Vektor mal Vektor ergibt einen Skalar) – Dies ist inspiriert aus der Physik durch Arbeit = Kraft mal Weg.
Wir werden sehen, dass so ein Skalarprodukt dann eine “Norm” induziert und damit eine Metrik, wodurch z.B. Grenzwertprozesse möglich werden.
Einen \(\mathbb{R}\)-Vektorraum mit Skalarprodukt nennt man auch einen Euklidischen Raum, einen \(\mathbb{C}\)-Vektorraum mit Skalarprodukt nennt man auch Hilbertraum – genauer Prähilbertraum.
Für die Anwendungen z.B. in der Physik spielt es eine große Rolle, welches der Körper zum Vektorraum ist. In der Quantenphysik benötigt man dazu den Körper der Komplexen Zahlen: \(\mathbb{C}\)
Definition des Skalarprodukts
Das Skalarprodukt zweier Vektoren wird axiomatisch wie folgt definiert.
Axiomatische Definition
Generell ist das Skalarprodukt f in einem Vektorraum über dem Körper K eine Abbildung:
\( f: V \times V \to K \)
Man schreibt auch gerne das Skalarprodukt als:
\( \Large f(x,y) = \langle x,y \rangle \)
\( \Large f(x,y) = \vec{x} \cdot \vec{y} \)
Für den Fall eines Vektorraums über dem Körper der reelen Zahlen, müssen für x, y, z ∈ V und λ ∈ \(\mathbb{R} \) folgende Axiome gelten:
Linearität in beiden Argumenten
<x+y,z> = <x,z> + <y,z>
<x,y+z> = <x,y> + <x,z>
<λx,y> = λ <x,y>
<x,λy> = λ <x,y>
Symmetrie: <x,y> = <y,x>
Positiv definit:
<x,x> ≥ 0
<x,x> = 0 genau dann, wenn x=0 ist
Das reelle Skalarprodukt ist also eine positiv definite, symmetrische Bilinearform.
Für den Fall eines Vektorraums über dem Körper der komplexen Zahlen, ist die Sache etwas schwieriger.
Da wir aber in der Quantenphysik Vektorräume über den komlexen Zahlen benötigen, müssen wir auch diesen etwas komplizierteren Fall näher betrachten.
Es müssen für x, y, z ∈ V und λ ∈ \(\mathbb{C} \) folgende Axiome gelten:
Semilinear im ersten Argument:
\( <\lambda x, y> = \bar{\lambda} <x,y> \)
Linear im zweiten Argument:
\( <x, \lambda y> = \lambda <x,y> \)
Hermitisch:
\( <x,y> = \overline{<y,x>} \)
Positiv definit:
<x,x> ≥ 0
<x,x> = 0 genau dann, wenn x=0
Das komplexe Skalarprodukt ist also eine positiv definite, hermitische Sesquillinearform.
Existenz eines Skalarprodukts bei endlicher Dimension
Soweit ist dies eine axiomatische Definition von Eigenschaften, welche ein Skalarprodukt erfüllen muss. Die Frage ist allerdings, für einen bestimmten Vektorraum, ob dort auch tatsächlich ein solches Skalarprodukt definiert werden kann.
Aus unserem Vektorraum V über K nehmen wir zwei Vektoren \(\vec{x}\) und \(\vec{y}\) und versuchen deren Skalarprodukt zu definieren. Im Falle einer endlichen Dimension des Vektorraums dim(V)=n können wir das leicht über die Komponentendarstellung dieser Vektoren zu einer ausgewählten Vektorbasis erreichen:
Wir könnten das Skalarprodukt zweier beliebiger Vektoren also definieren, wenn wir nur das Skalaprodukt von je zwei Basisvektoren so definieren, dass dann die Axiome des Skalarprodukts eingehalten würden. Mit anderen Worten: Bei geeigneter Festlegung einer Matrix:
\( g_{ij} = \vec{g}_i \cdot \vec{g}_j \tag{1}\)
Könnten wir das Skalarprodukt einfach definieren als:
Wir bekommen also ein Objekt aus zweifach indizierten Skalaren (genannt Metrik-Koeffizienten). Diese Metrik-Koeffizienten bilden also eine quadratische Matrix, die wir später auch gerne “Metrik-Tensor” nennen werden.
Der Metrik-Tensor besteht also aus den paarweisen Skalarprodukten der verwendeten Basisvektoren.
Beispiel:
Wie nehmen einen euklidischen Vektorraum: \(\mathbb{R}^3\)
mit der Vektorbasis: \( \vec{e}_i = (\delta_{i}^j) \)
Wir nehmen als Metrik-Tensor: \( \eta_i^j = \left( \begin{matrix} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \\ \end{matrix} \right) \)
Aus Gleichung (2) mit dem obigen Metrik-Tensor ergibt sich als Skalarprodukt:
Um hier das Skalarprodukt auszurechnen nach Gleichung (2) müssen wir die Komponenten der Vektoren bestimmen. Dazu nehmen wir ersteinmal die Komponenten der einzelnen Vektoren:
Somit ist das Skalarprodukt im ersten Argument linear unabhängig von der Wahl des Metrik-Tensors.
Das Skalarprodukt ist auch im zweiten Argument linear, wenn der Skalaren-Körper \(\mathbb{R}\) ist – dann gilt die obige Herleitung identisch.
Das zweite zu überprüfende Axiom wäre die Symmetrie
Nach unserer Definition des Skalarprodukts in Gleichung (2) gilt:
\( \langle x, y \rangle = x^i y^j g_{ij} \)
und
\( \langle y, x \rangle = y^j x^i g_{ji} = x^i y^j g_{ji}\)
Wir sehen also, dass wenn der Metrik-Tensor symmerisch ist (gij = gji), dann ist auch das damit definierte Skalarprodukt symmetrisch.
Das dritte zu überprüfende Axiom wäre die Positive Definitheit
Dies ergibt sich auch ganz einfach.
Skalarprodukt bei nicht-endlicher Dimension
Ein Vektorraum nicht-endlicher Dimension über K ist so etwas wie ein Funktionenraum. Für \( f \in V \text{ und } g \in V \) definieren wir das Innere Produkt (Skalarprodukt) als:
Die komplexe Konjugation wird hier u.a. benötigt, damit die Länge eines Vektors (s.u.) eine reele Zahl wird.
Unitäre Abbildung (Unitäre Transformation)
Eine Abbildung (auch Transformation genannt) von einem Vektorraum V in einen anderen W wird “unitär” genannt, wenn sie das Skalarprodukt “erhält” (Da die Länge eines Vektors über das Skalarprodukt definiert ist, ist eine unitäre Abbildung längentreu)
Nehmen wir zwei Vektorräume V und W, jeweils mit einem Skalarprodukt, sowie eine Abbildung:
\( f: V \to W \)
Dann soll für je zwei Vektoren u und v aus V gelten:
\( <f(u),f(v)> = <u,v>\\ \)
Man kann zeigen, dass solche unitären Abbildungen auch stets lineare Abbildungen sind.
Ein klassisches Beispiel ist die Gruppe U(1) der komplexer Zahlen vom Betrag Eins, wobei die Gruppen-Verknüpfung die Multiplikation der komplexen Zahlen (also die Drehung) ist. Diese Gruppe spielt bei dem Standardmodell der Teilchenphysik eine wichtige Rolle. Die Gruppe U(1) bildet ein mathematisches Modell der Elektrostatischen Wechselwirkung in der Quanten-Elektrodynamik mit dem Photon als Austauschteilchen.
Länge eines Vektors
Der Begriff “Metrik-Tensor” hat schon einen Sinn, wenn wir sehen, dass damit auch die Länge eines Vektors definiert werden kann: