Gehört zu: Vektor-Analysis
Siehe auch: Metrik-Tensor
Kontravariante Ableitung
xyz

Gehört zu: Tensoren
Siehe auch: Metrik-Tensor, Astronomische Koordinatensysteme, Raumkrümmung
Benutzt: Latex-Plugin
Stand: 23.10.2024
Prof. Wagner: https://youtu.be/c07r4pARzHw
In der Geometrie führt man gerne Koordinatensysteme ein, um die geometrischen Objekte (Punkte, Linien, Geraden, Flächen,…) mithilfe von Zahlen (Koordinaten) zu beschreiben und zu untersuchen. Das führt zur sog. Analytischen Geometrie.
Man spricht gerne von der Eukidischen Geometrie, dem Euklidischen Raum und den Euklidischen Koordinaten.
Nach Rene Decartes (1596-1650) nennt man die Euklidischen Koordinaten auch “Kartesische Koordinaten”.
Im herkömmlichen unserer Anschauung entsprechenden dreidimensionalen Raum \(\mathbb{R}^3 \) haben wir ja die klasssichen Kartesischen Koordinaten mit den Symbolen: x, y, z. Im höherdimensionalen Falle schreibt man dann eher x1, x2, x3, x4,…
Man hat eine Menge M (Punktmenge) und ordnet jedem Element (Punkt) aus M ein-ein-deutig ein n-Tupel von Koordinaten zu. Dann kann man statt der Punkte über diese n-Tupel (also die n Koordinaten) sprechen.
So eine Koordinate ist im einfachsten Fall eine reelle Zahl, dann sind die Koodinaten also n-Tupel reeller Zahlen, also Elemente aus dem \( \mathbb{R}^n \). Im allgemeinen Fall nehmen wir für die Koordinaten einen Körper.
Wir hätten also eine ein-ein-deutige (d.h. bijektive) Abbildung zwischen Punkten aus M und n-Tupeln:
\( M \to \mathbb{R}^n \)So eine Menge zusammen mit einem Koordinatensystem nennen wir (nach Bernhard Riemann 1816-1866) eine Mannigfaltigkeit.
In der Mathematik werden Mannigfaltigkeiten für sich noch sehr detailliert in genauer als hier behandelt. Für uns ist es wichtig zu einem Koordinatensystem zu kommen.
Im herkömmlichen unserer Anschauung entsprechenden dreidimensionalen Raum \(\mathbb{R}^3 \) habe wir ja die klasssichen Kartesischen Koordinaten mit den Symbolen: x, y, z. Im höherdimensionalen Falle schreibt man dann eher x1, x2, x3, x4,…
Bei nicht-kartesischen Koordinaten, die wir als “allgemeine Koordinaten” bezeichnen, verwenden wir im allgemeinen die Symbole qi (i=1,2,..). Diese “allgemeinen Koordinaten” nennt man, um den Gegensatz zu den Kartesischen Koordinaten deutlich zu machen, auch gerne krummlinige Koordinaten.
Typische Beispiele für krummlinige Koordinaten sind z.B.
Krummlinige Koordinaten gibt es auch in einem “flachen” Raum; z.B. ebene Polarkoordinaten.
Kartesische Koordinaten im “gekrümmten” Raum sind (global) nicht möglich (Raumkrümmung -> Krümmungstensor).
Eine Kurve in einer Manigfaltigkeit M wird gegeben durch eine Abbildung von einem reellen Intervall auf Punkte in die Manigfaltigkeit. Man nennt so eine Abbildung auch eine Parameterdarstellung der Kurve.
Den Parameter aus einem reellen Intervall können wir schreiben als: \( t \in [t_a, t_e] \)
Die Abbildung ist dann:
\( [t_a, t_e] \to M \\\)Wir haben also zu jedem Parameterwert \( t \in [t_a, t_e] \) einen Punkt aus der Manigfaltigkeit M.
Wenn wir den Punkt durch seine Koordinaten \( \left(q^i\right) \) ausdrücken, ist die Kurve also eine Abbildung:
\( [t_a, t_e] \to \mathbb{R}^n \\\)Wo also die Koordinaten qi eine Funktion des Parameters t sind: \( q^i = q^i(t) \)
Wenn die Kurve differenzierbar ist (also die Koordinaten der Parameterdarstellung), hat die Kurve auch Tangentenvektoren:
\(\vec{T}(t) = \left(T^i(t)\right) = \Large \left(\frac{dq^i}{dt} \right) \)Die Kurve selbst liegt in der Manigfaltigkeit; der Tangentenvektor aber nicht, er ist an die Mannigfaltigkeit sozusagen “angeheftet”.
Die Tangentenvektoren liegen in einem eigenen Vektorraum…
Ganz einfache Formen einer Kurve sind die sog. Koordinatenlinien.
Bei einem n-dimensionalen Koordinatensystem erhält man eine Koordinatenlinie indem man n-1 Koordinaten festhält und genau eine Koordinate als Parameter laufen lässt. So eine Koordinatenlinie kann man als (unendliche) Kurve auffassen.
Durch jeden Raumpunkt \( (p^i) = \left( p^1, p^2,\ldots, p^n \right)\) gehen dann n Koordinatenlinien: \( L_j\) mit \( j=1, 2,\ldots, n \).
Die Koordinatenlinie \( L_j\) hat den Parameter \( t = q^j \) und die Werte:
\( q^i(t) = p^i \enspace (\text{falls } i \neq j) \)
\( q^i(t) = t \enspace (\text{falls } i = j) \)
Schöneres Latex:
\( q^i(t) = \left \{ \begin{array}{ll} p^i & \text{falls } i \neq j \\ t & \text{falls } i = j \\ \end{array} \right. \)Bei einem n-dimensionalen Koordinatensystem bekommt man Koordinaten-Hyperflächen in dem man genau eine Koordinate festhält und alle anderen laufen lässt.
Durch jeden Raumpunkt \( (p^i) = \left( p^1, p^2,\ldots, p^n \right) \) gehen dann n Koordinaten-Hyperflächen.
So eine Koordinaten-Hyperfläche kann man als sog. Teil-Mannigfaltigkeit auffassen.
Nun kann man an jedem Raumpunkt anhand des Koordinatensystems eine Vektorbasis definieren…
In jedem Raumpunkt kann man nun Basisvektoren so definieren, dass deren Länge 1 sei und sie Tangenten an die Koordinatenlinien durch diesen Punkt sind.
Hierzu habe ich einen eigenen Artikel Astronomische Koordinatensysteme geschrieben.
Gehört zu: Vektoranalysis
Siehe auch: Allgemeine Relativitätstheorie, Koordinatensysteme, Vektorbasis, Tensoren, Gekrümmter Raum
Stand: 26.10.2021
Youtube-Videos von Prof. Paul Wagner:
Wir betrachten eine Riemansche Manigfaltigkeit; d.h. eine Punktmenge mit einem Koordinatensystem. Zu so einem Koordinatensystem, gehört ein Metrik-Tensor, der uns auch ein Linienelement definiert und damit so etwas wie eine Metrik.
Wir kommen aber nicht in einem Schritt von einem Koordinatensystem zu einem Metrik-Tensor, sondern betrachten zunächst, wie ein Koordinatensystem eine Vektorbasis definiert. Zu so einer Vektorbasis haben wir dann einen Metrik-Tensor.
Schlussendlich wollen wir ja Vektorfelder beschreiben. Dabei handelt es sich ja um eine Abbildung von Raumpunkten auf Vektoren. Dabei wird der Raumpunkt durch seine Koordinaten im Koordinatensystem und der Vektor durch seine Komponenten bezügliche “seiner” Vektorbasis beschieben. Wenn wir dann beispielsweise die Veränderung eines Vektors bei kleinen Veränderungen des Raumpunkts untersuchen, müssen wir nicht nur die Veränderung der Vektorkomponenten, sondern ggf. auch die Veränderung der Basisvektoren berücksichtigen, da die Basisvektoren ja im Allgemeinen (z.B. bei krummlinigen Koodinaten) auch vom Ort im Raum abhängig sein werden.
Das wird uns dann zur sog. Kontravarianten Ableitung führen.
Zu einem Koordinatensystem bekommmen wir nämlich zwei möglicherweise verschiedene Vektorbasen:
1) Die Basisvektoren sind tangential zu den Koordinatenlinien: sog. kovariante Basis
2) Die Basisvektoren stehen normal (senkrecht) auf den Koordinatenhyperflächen: sog. kontravariante Basis
Bei Chartesischen Koordinaten sehen wir Besonderheiten:
Bei nicht-chartesischen Koordinatensystemen (sog. krummlinigen) wird das beides anders sein.
Bei solchen nicht-chartesischen Koordinaten, die wir als “allgemeine Koordinaten” bezeichnen, verwenden wir im allgemeinen die Symbole qi (i=1,2,..). Diese “allgemeinen Koordinaten” nennt man, um den Gegensatz zu den Chartesischen Koordinaten deutlich zu machen, auch gerne krummlinige Koordinaten.
Wir betrachten nun einen Raum mit den allgemeinen (krummlinigen) Koordinaten: \( q^\alpha \) mit α =1,2,…,n und einem hilfsweise dahinterliegenden Chartesischen Koordinaten: \( x^i \) mit 1= 1,2,….n.
Als Hilfsmittel ziehen wir anfangs gerne die Chartesischen Koordinaten hinzu, wo wir dann im Fall von beliebig vielen Dimensionen die Symbole xi (i=1,2,…) verwenden, oder bei zwei und oder drei Dimensionen, manchmal auch: x,y,z.
Die kovarianten Basisvektoren nennen wir:
\(\Large {\vec{g}}_\alpha \) wobei α=1,2,..,n
Diese Basisvektoren sind Tangenten an die Koordinatenlinien. Demnach sind die Komponenten (i=1,2,…n) dieser Basisvektoren im Chartesischen Koordinatensystem:
\(\Large \left( \vec{g}_\alpha \right)^i = \frac{\partial x^i}{\partial q^\alpha} \)Die kontravarianten Basisvektoren nennen wir:
\(\Large {\vec{g}}^{\,\alpha} \) wobei α=1,2,..,n
Diese Basisvektoren sind Normalen auf den Koordinatenhyperflächen. Demnach sind die Komponenten (i=1,2,…n) dieser Basisvektoren im Chartesischen Koordinatensystem:
\( \Large \left( {{\vec{g}}^{\,\alpha}} \right)^i = \frac{\partial q^\alpha}{\partial x^i} \)Wenn wir eine Vektorbasis gefunden haben; z.B.:
Eine Vektorbasis: \( \vec{g}_\alpha \) (α= 1,2,…,n)
Erhalten wir zu dieser Vektorbasis den dazugehörigen Metrik-Tensor als: \( \left(g_{ij}\right) = \vec{g}_i \cdot \vec{g}_j \)
Merke: Zu einer Vektorbasis haben wir einen Metrik-Tensor.
Wir können auf einer Riemannschen Mannigfaltigkeit ein Tensor-Feld \( g_{ij} \) definiert haben, mit dem wir einen Abstandsbegriff (d.h. eine Metrik) definieren; genauer gesagt, mit dem wir die Länge einer Kurve in der Mannigfaltigkeit definieren wie folgt:
\(\Large s = \int\limits_{t_a}^{t_b} \sqrt{g_{ij}\frac{dq^i}{dt}\frac{dq^j}{dt}} \, dt \)So einen Tensor \( g_{ij} \) nennen wir Metrik-Tensor.
Der Metrik-Tensor ist also ein Tensor-Feld, das auf einer Riemannschen Mannigfaltigkeit definiert ist.
Das Linienelement ist:
\( ds^2 = d{x_1}^2 + d{x_2}^2 + d{x_3}^2 + … \)Also:
\( ds^2 = \sum\limits_{i=1}^{n}{{dx_i}^2} \)Der Metrik-Tensor ist dabei ja ein Tensor vom Rang 2 und ist in diesem chartesischen Falle identisch mit der Einheitsmatrix (beispielsweise mit 3 Dimensionen):
\(\Large (g_{ij}) = \left[ \begin{array}{rrr} 1 & 0 & 0\\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{array} \right] \\\)Dieser Metrik-Tensor definiert dann unser Linienelement:
\( (ds)^2 = \sum\limits_{i=1}^n{\sum\limits_{j=1}^n{dx_i dx_j g_{ij}}} \)Oder in der Einsteinschen kompakten Schreibweise (mit der sog. Summenkonvention):
\( (ds)^2 = g_{ij} dx^i dy^j \)Im zweidimensionalen Euklidischen Raum (Ebene) haben wir als Chartesische Koordinaten: x1 = x, x2 = y
Als krummlinigen Koordinaten nehmen wir Polarkoordinaten: q1 = r und q2 = φ
Zum Rechnen verwenden wird als Hilfsmittel gern die Chartesischen Koordinaten. Damit haben wir Koordinaten-Transformationen in beiden Richtungen:
\( x = r \cdot \cos{\phi} \\ \\ y = r \cdot sin{\phi} \)Und in der anderen Richtung ist:
\( r = \sqrt{x^2 + y^2} \\ \phi =\arctan{\frac{y}{x}} \)Zu diesen Koordinaten erhalten wir als kovariante Vektorbasis (Basis Vektorsystem):
\( \left( \vec{g}_\alpha \right)^i = \frac{\partial x^i}{\partial q^\alpha} \)Zu diesen kovarianten Basisvektoren bekommen wir als kovarianten Metrik-Tensor:
\( \left(g_{ij}\right) = \left[ \begin{array}{rr} 1 & 0 \\ 0 & r^2 \end{array} \right] \\\)Wobei dieses Beispiel zeigt: (1) Der Metrik-Tensor ist ortsabhängig und (2) Die zugrundeliegende Vektorbasis ist zwar orthogonal, aber nicht orthonormal.
Und entsprechend das kovariante Linienelement:
\( (ds)^2 = dr^2 + r^2 d\phi^2 \\ \)Zu diesen Koordinaten erhalten wir als kontravariante Vektorbasis:
\( \left( {{\vec{g}}^{\,\alpha}} \right)^i = \frac{\partial q^\alpha}{\partial x^i} \\\)Zu diesen kontravarianten Basisvektoren bekommen wir als kontravarianten Metrik-Tensor (wir können die Komponenten des kontravarianten Metrik-Tensors ausrechnen oder nehmen einfach das Inverse des kovarianten Metriktensors):
\( \left(g^{ij}\right) = \left[ \begin{array}{rr} 1 & 0 \\ 0 & \frac{1}{r^2} \end{array} \right] \\\)Und entsprechend das kontravariante Linienelement:
\( (ds)^2 = dr^2 + \frac{1}{r^2} d\phi^2 \)Wir sehen auch, dass die beiden Metrik-Tensoren invers zueinander sind.
Im dreidimensionalen euklidischen Raum können wir neben den Chartesischen Koordinaten x ,y, z die Zylinderkoordinaten (r, φ, z) betrachten.
Dies sind also allgemeine (krummlinige) Koordinaten mit \( q^1 = r, \, q^2 = \phi, \, q^3 = z \)
Aufgrund der Koordinaten-Transformationen bekommen wir:
Für den kovarianten Metrik-Tensor:
\( \left(g_{ij}\right) = \left[ \begin{array}{rrr} 1 & 0 & 0 \\ 0 & r^2 & 0 \\ 0 & 0 & 1 \end{array} \right] \\\)Und entsprechend das kovariante Linienelement:
\( (ds)^2 = dr^2 + r^2 d\phi^2 + dz^2 \\ \)Und für den kontravarianten Metrik-Tensor bekommen wir:
\( \left(g_{ij}\right) = \left[ \begin{array}{rrr} 1 & 0 & 0 \\ 0 & \frac{1}{r^2} & 0 \\ 0 & 0 & 1 \end{array} \right] \\\)Und entsprechend das kontravariante Linienelement:
\( (ds)^2 = dr^2 + \frac{1}{r^2} d\phi^2 + dz^2 \)Wiederum sehen wir auch, dass die beiden Metrik-Tensoren invers zueinander sind.
Im dreidimensionalen euklidischen Raum können wir neben den Chartesischen Koordinaten x, y, z die Kugelkoordinaten (r, θ, φ) betrachten.
Dies sind also allgemeine (krummlinige) Koordinaten mit \( q^1 = r, \, q^2 = \theta, \, q^3 = \phi \)
Als kovariante Vektorbasis bekommen wir wieder die Tangenten an die Koordinatenlinien, also an die “Radialachse” (Zenith/Nadir), die “Meridiane” (Nord/Süd) und die “Breitenkreise” (Ost/West).
Als kovarianten Metrik-Tensor bekommen wir:
\( \left(g_{ij}\right) = \left[ \begin{array}{rrr} 1 & 0 & 0 \\ 0 & r^2 & 0 \\ 0 & 0 & r^2 \sin^2 \theta \end{array} \right] \\\)Und entsprechend das kovariante Linienelement:
\( (ds)^2 = dr^2 + r^2 d\theta^2 + r^2 \sin^2 \theta \, d\phi^2 \\ \)Und als kontravarianten Metrik-Tensor bekommen wir:
\( \left(g_{ij}\right) = \left[ \begin{array}{rrr} 1 & 0 & 0 \\ 0 & \frac{1}{r^2} & 0 \\ 0 & 0 & \frac{1}{r^2 \sin^2 \theta} \end{array} \right] \\\)Und entsprechend das kontravariante Linienelement:
\( (ds)^2 = dr^2 + \frac{1}{r^2}d\theta^2 + \frac{1}{r^2 \sin^2 \theta}d\phi^2 \)Wiederum sehen wir auch, dass die beiden Metrik-Tensoren invers zueinander sind.
Die Oberfläche einer Kugel mit dem (festen) Radius R ist ein zweidimensionaler Raum, wo wir als Koordinatensystem gut mit dem entsprechenden Teil der Kugelkkordinaten arbeiten können.
Also mit den allgemeinen (krummlinigen) Koordinaten mit \( q^1 = \theta, \, q^2 = \phi \), was also auf der Erdoberfläche prinzipiell der geografischen Breite und der geografischen Länge entsprechen würde.
Als kovariante Vektorbasis bekommen wir wieder die Tangenten an die Koordinatenlinien, also an die “Meridiane” (Nord/Süd) und die “Breitenkreise” (Ost/West).
Der Metrik-Tensor ergiebt sich dann ganz analog aus dem Vorigen:
Als kovarianten Metrik-Tensor bekommen wir:
\( \left(g_{ij}\right) = \left[ \begin{array}{rr} R^2 & 0 \\ 0 & R^2 \sin^2 \theta \end{array} \right] \\\)Und entsprechend das kovariante Linienelement:
\( (ds)^2 = R^2 d\theta^2 + R^2 \sin^2 \theta \, d\phi^2 \\ \)Der so definierte Riemansche Raum (Kugeloberfläche mit dem o.g. Koordinatensystem) ist ein Nichteuklidischer Raum, wie wir sehen werden. Zur Geometrie in solchen Nichteuklidischen Räumen haben wir ja noch nichts gesagt; aber die Standard-Weissheit ist ja die Winkelsumme im Dreieck und…
Gehört zu: Mathematik
Siehe auch: Lineare Algebra
Benutzt: WordPress-Plugin Latex
Jede (nxm)-Matrix ist per Matrixmultipikation eine lineare Abbildung von \(\mathbb{R}^m\) nach \(\mathbb{R}^n\)
Quelle: https://www.mathematik.de/algebra/74-erste-hilfe/matrizen/2429-lineare-abbildungen
Eine Lineare Abbildung kann eindeutig beschrieben werden durch die Werte auf die die Basis-Vektoren einer Basis abgebildet (transformiert) werden.
Beispielsweise heisst das im Vektorraum \(\mathbb{R}^2\) mit dem kanonischen Koordinatensystem und den Basisvektoren \( \hat{i} \) und \( \hat{j} \) folgendes:
Wenn wir einen Vektor \( \vec{v} = \left[ \begin{array}{c} x \\\ y \end{array} \right] = x \hat{i} + y\hat{j} \) betrachten, so wirkt eine Lineare Transformation L wie folgt:
\( L(\vec{v}) = x L(\hat{i}) + y L(\hat{j} ) \)Wenn wir also die transformierten Basisvektoren \( L(\hat{i}) \) und \( L(\hat{j}) \) kennen, ist damit die Lineare Transformation L vollständig festgelegt.
Diese transformierten Basis-Vektoren können im verwendeten Koordinatensystem als Matrix schreiben.
Wenn bei unserer Linearen Transformation beispielsweise \( L(\hat{i}) = \left[ \begin{array}{c} 3 \\\ -2 \end{array} \right] \) und \( L(\hat{j}) = \left[ \begin{array}{c} 2 \\\ 1 \end{array} \right] \) wäre, bekämen wir eine Matrix:
\( \left[ L(\hat{i}) | L(\hat{j}) \right] = \left[ \begin{array}{rr} 3 & 2 \\ -2 & 1 \\ \end{array} \right] \)Wir “konkatenieren” also die transformierten Basis-Vektoren vertikal als Spalten.
Die Lineare Transformation kann im benutzten Koordinatensystem als Matrixmultiplikation aufgefasst werden:
Völlig analog werden auch Lineare Transformationen in drei oder mehr (endlichen) Dimensionen behandelt.
Viele der Überlegungen, die wir mit Linearen Abblidungen vorgenommen haben, können wir also gleichermaßen auf Matrizen übertragen.
Sei also A die (nxn)-Matrix zur Linearen Abblidung L von einem Vektorraum V in einen Vektorraum W (beide über dem gleichen Körper K)
\( L: V \to W \\\)So haben wir beispielsweise zu L im Falle dim(V) = dim(W) = 3 eine (3×3)-Matrix A:
\(\Large A = \left( \begin{array}{rrr} a_{11} & a_{12} & a_{13}\\ a_{21} & a_{22} & a_{23} \\ a_{31} & a_{32} & a_{33} \end{array} \right) \\\)Das Bild (engl. image) der Matrix A ist die Menge:
\( im(A) =\{ y \in W \,| \,\exists x \in V \, : \, Ax = y \} \\\)im(A) ist wiederum ein Untervektorraum von W.
Der Rang einer Matrix ist die Anzahl linear unabhängiger Zeilen- oder Spaltenvektoren der Matrix.
Bei einer quadratischen (n×n)-Matrix bedeutet dies, er ist höchstens n.
Rang(A) = dim(im(A))
Der Kern der Matrix A ist die Menge der Vektoren, die auf den Null-Vektor abgebildet werden:
\( ker(A) =\{ x \in V \,| \, Ax = 0 \} \\\)ker(A) ist wiederum ein Untervektorraum von V.
Mit anderen Worten: Der Kern von A ist also die Lösungsmenge des Linearen Gleichungssystems Ax=0
Bei einer quadratischen (n×n)-Matrix ist die Determinante genau dann 0 ist, wenn ihr Rang der Matrix kleiner n ist.
Gehört zu: Mathematik
Siehe auch: Vektorräume, Quantenfeldtheorie
Benutzt: WordPress Plugin for Latex
Stand: 23.2.2022
Ein Vektorraum V über einem Körper K zusammen mit einer bilinearen Abbildung:
\( V \times V \to V \)wird eine Algebra genannt.
Die bilineare Abbildung wird “Produkt” (auch: Multiplikation) genannt und auch so wie ein Produkt hingeschrieben; also: a · b oder einfach ab. In dieser Schreibweise bedeutet die Bilinearität einfach folgendes:
\( (x + y) \cdot z = x \cdot z + y \cdot z \\ \)
\( x \cdot (y + z) = x \cdot y + x \cdot z \\ \)
\( a (x \cdot y) = (ax) \cdot y = x \cdot (ay) \\ \)
Dabei sind x, y und z Vektoren aus V und a ein Skalar aus K.
Das “besondere” an Algebren ist die “Multiplikation”. Deswegen unterscheidet man Algebren auch nach den Eigenschaften dieser Multiplikation:
Kommutative – nicht-kommutative Algebren: Ist immer \( a \cdot b = b \cdot a \) oder nicht?
Assoziative – nicht-assoziative Algebren: Ist immer \( a \cdot (b \cdot c) = (a \cdot b) \cdot c \) oder nicht?
Die n × n Matrizen über einem Körper mit der gewöhnlichen Matrizenmultiplikation als “Multiplikation” bilden eine assoziative Algebra.
Ein Vektorraum V mit dem Kreuzprodukt als Multipikation bildet eine nicht-assoziative Algebra.
Bestimmte Algebren heissen “Lie-Algebren” (nach Sophus Lie 1842-1899), dort wird das Produkt meist als [x,y] geschrieben und “Lie-Klammer” genannt.
Eine Lie-Algebra ist eine Algebra, in der die beiden folgenden Bedingungen gelten:
Ein Vektorraum V mit dem Kreuzprodukt als Multipikation bildet eine Lie-Algebra.
Im allgemeinen definiert man als Kommutator in Ringen und assoziativen Algebren: [a,b] = ab – ba
So ein Kommutator kann in bestimmten Algebren als Lie-Klammer fungieren. Beispielsweise kann man aus der oben erwähnten Algebra der n x n Matrizen mit der gewöhnlichen Matrixmultiplikation eine Lie-Algebra machen, indem man den Kommutator der Matrixmultiplikation als Lie-Klammer nimmt.
Solche Lie-Algebren werden in der Quantenfeldtheorie praktisch gebraucht.
Gehört zu: Mathematik
Siehe auch: Krümmung, Vektorraum, Wirkung, Schwarzschild-Metrik, Metrik-Tensor
Benutzt: WordPress-Plugin Latex, GeoGebra Grafikrechner
Stand: 19.10.2021
Auf einer Menge M kann man eine Metrik definieren; dadurch dass man je zwei Punkten einen Abstand (relle Zahl >= Null) zuordnet.
d: M x M -> R
So eine Abstandsfunktion muss drei Axiome erfüllen, um Metrik genannt werden zu dürfen.
Oft ist den Beispielen die Menge M ein Vektorraum z.B. R2 oder R3.
Mit Hilfe einer solchen Metrik kann man eine ganze “Geometrie” definieren, also ein Regelwerk für Punkte, Geraden, Winkel, Dreiecke etc. Klassisch ist die Geometrie nach Euklid; andere Geometrien bezeichnet man als “Nicht-Euklidische Geometrie”…
In der sog. Euklidischen Geometrie wird der Abstand im zweier Punkte im Raum (also die Metrik) durch den Satz des Pythagoras definiert.
Zur Berechnung des Abstands zweier Punkte verwenden wir ein Koordinatensystem z.B. im R3 eine x-Achse, eine y-Achse und eine z-Achse:
\(\Large d((x_a,y_a,z_a),(x_b,y_b,z_b)) = \sqrt{(x_b-x_a)^2 + (y_b-y_a)^2 – (z_b-z_a)^2} \\\ \)Dieser Abstand ist auch die Länge der geraden Strecke zwischen den Punkten a und b.
Im allgemeinen Fall nehmen wir eine parametrisierte Kurve α: [a,b] -> Rn und definieren als Länge L der Kurve α:
\(\Large L_\alpha(a,b) = \int_a^b ||\alpha^\prime(t)|| dt \\\ \)Siehe auch: Integralrechnung
Wir können zeigen, dass diese Längendefinition für Kurven mit der Metrik für Punktabstäde im Euklidischen Raum überein stimmt (ohne Beschänkung der Allgemeinheit: t ∈ [0,1]):
\( \alpha(t) = \left( \begin{array}{c} x_1 + (x_2-x_1) \cdot t \\\ y_1 + (y_2-y_1)\cdot t \\\ z_1 + (z_2-z_1)\cdot t\end{array}\right) \\\ \)Die erste Ableitung ist:
\( \alpha^\prime(t) = \left( \begin{array}{c} (x_2-x_1) \\\ (y_2-y_1) \\\ (z_2-z_1) \end{array}\right) \\\ \)Die Norm der Ableitung ist dann:
\( || \alpha^\prime(t) || = \sqrt{(x_2-x_1)^2 + (y_2-y_1)^2 + (z_2-z_1)^2} \\\ \)Wenn wir das in die obige Längendefinition einsetzen erhalten wir:
\( L_\alpha(a,b) = \int_a^b ||\alpha^\prime(t)|| dt = \sqrt{(x_2-x_1)^2 + (y_2-y_1)^2 + (z_2-z_1)^2} \int_0^1 dt = \sqrt{(x_2-x_1)^2 + (y_2-y_1)^2 + (z_2-z_1)^2} \\\ \)Die Länge einer geraden Strecke ist also auch mit der allgemeinen Integral-Formel genauso wie nach Pythagoras oben.
Gerne verwendet man auch ein sog. Linienelement um eine Metrik zu definieren. Für die Euklidische Metrik im dreidimensionalen Raum mit einem Chartesischen Koordinatensystem (x,y,z) haben wir das Linienelement:
\( ds^2 = dx^2 + dy^2 + dz^2 \\\ \)Was ergibt:
\( ds = \sqrt{dx^2 + dy^2 + dz^2} \\\ \)Was für eine parametrisierte Kurve s: [a,b] -> R3 bedeutet:
\( \Large \frac{ds}{dt} = \sqrt{(\frac{dx}{dt})^2 + (\frac{dy}{dt})^2 + (\frac{dz}{dt})^2} \\\ \)Was als Kurvenlänge von t=a bis t=b ergibt:
\( \Large L(a,b) = \int_a^b \sqrt{(\frac{dx}{dt})^2 + (\frac{dy}{dt})^2 + (\frac{dz}{dt})^2} dt \\\ \)Wenn man nun bedenkt dass:
\(\Large s^\prime = \frac{ds}{dt} = \left( \begin{array}{c} \frac{dx}{dt} \\\ \frac{dy}{dt} \\\ \frac{dz}{dt} \end{array}\right) \\\ \)ist, ergibt sich die Norm zu:
\( ||\Large s^\prime || = \sqrt{(\frac{dx}{dt})^2 + (\frac{dy}{dt})^2 + (\frac{dz}{dt})^2} \\\ \)Eingesetzt ergibt das:
\( \Large L(a,b) = \int_a^b || s^\prime || dt \\\ \)was genau der ersten Definition (oben) entspricht.
Man kann auch zeigen, dass die so definierte Länge einer parametrisierten Kurve bei Umparametrisierungen der Kurve gleich bleibt.
Im allgemeinen Fall drücken wir das Linienelement in einem Koordinatensystem mithilfe des “Metrik-Tensors” \(g_{\mu\nu}\) aus:
\( ds^2 = g_{\mu\nu} dx^\mu dx^\nu \\\ \)Im Falle der Euklidischen Geometrie im R3 ist im Chartesischen Koordinatensystem der metrische Tensor:
\( g = \left[ \begin{array}{rrr} 1 & 0 & 0\\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{array} \right] \\\)Ein “Tensor” in diesem Sinne ist nichts anderes als eine (n x n)-Matrix für die man noch einige zusätzliche Regeln hat.
Nach der Allgemeinen Relativitätstheorie ART von Einstein, verändert die Anwesenheit von Materie den Raum, was auch “Gravitation” genannt wird.
Wir können das als eine Nicht-Euklidische Metrik verstehen, für die beispielsweise Karl Schwarzschild schon 1916 im vereinfachten Fall einer Kugelmasse (Schwarzes Loch) eine Formel gefunden hat.
Zu Veranschaulichung so einer Nicht-Euklidischen Metrik wird häufig von einer “Krümmung” der Raumzeit gesprochen. Diese “Krümmung” ist aber eigentlich nur eine andere Metrik, trotzdem stellt man sich die Abweichung von der herkömmlichen Euklidischen Metrik gern als “Krümmung” vor,
Da diese “Krümmung” (also Abweichung von der Euklidischen Metrik) aber nicht in eine weitere Dimension, sondern “in sich” d.h. als Stauchung bzw. Streckung erfolgt, würde ich gerne eine solche Abweichung durch ein Verbiegen des Koordinatengitters veranschaulichen. Also durch den optischen Vergleich der Koordinatengitter zweier Metriken.
===> Das Gitter, was ich hier meine, ist ein durch gleiche Abstände in der jeweiligen Metrik gegebenes Gitter – ist also eigentlich kein schlichtes Koordinatengitter, sondern ein Metrik-Gitter…
Ich habe zum Thema Schwarzschild-Metrik einen eigenen Artikel geschrieben.
Gehört zu: Physik
Siehe auch: Relativitätstheorie, Vektorraum, Gravitation, Schwarze Löcher, Metrik, Koordinatensysteme
Die Allgemeine Relativitätstheorie (ART) basiert auf dem Postulat der Äquivalenz von Gravitation und Beschleunigung.
Aus diesem Äquivalenzprinzip ergibt sich die Lichtablenkung in Gravitationsfeldern.
Wenn man trotzdem davon ausgehen möchte, dass das Licht immer den kürzesten Weg nimmt, muss die Gravitation den Raum (besser die Raumzeit) entsprechend krümmen, sodass eine Metrik entsteht bei der der kürzeste Weg zwischen zwei Punkten nicht unbedingt die Euklidische gerade Linie ist.
Wir wollen hier zunächsteinmal den Begriff der “Krümmung” ganz allgemein diskutieren.
Umgangssprachlich denkt man bei “Krümmung”, dass sich etwas in eine zusätzliche Dimension krümmt (s.u. die vielen Beispiele). Bei der von Einstein postulierten Krümmung der vierdimensionalen Raumzeit wird aber für diese Krümmung keine 5. Dimension gebraucht. Die vierdimensionale Raumzeit ist nach Einstein “in sich” gekrümmt; d.h. wir haben einen anderen Abstandsbegriff (eine andere Metrik, ein anderes Linienelement).
Unter der Krümmung eines geometrischen Objekts versteht man die Abweichung von einem geraden Verlauf; dazu bedarf es (mindestens) einer weiteren Dimension in die die Krümmung verläuft oder der Begriff “gerade” muss umdefiniert werden. Eine Kurve verläuft “gerade” wenn beim Durchlaufen mit konstanter Geschwindigkeit, keine Beschleunigungen “seitwärts”, sonder höchstens in der Normalen auftreten.
Wir betrachten eine Gerade. Solange sie wirklich geradeaus verläuft ist sie nicht gekrümmt. Wenn sie eine Kurve nach links (oder rechts) macht, haben wir eine Krümmung – und wir brauchen dafür (mindestens) eine zweite Dimension. Die Stärke der Krümmung kann mehr oder weniger sanft oder kräftiger sein. Wir messen die Stärke der Krümmung an einer Stelle durch einen sog. Krümmungskreis. Das ist ein Kreis, der sich in dem betrachteten Punkt am besten an die Kurve anschmiegt. Ein großer Krümmungskreis bedeutet eine kleine Krümmung ein kleiner Krümmungskreis ein starke Krümmung. Der Kehrwert des Radius ist das Maß für die Krümmungsstärke.
Die andere Frage ist, welche geometrischen Objekte sind es, die da “gekrümmt” werden? Im einfachsten Fall ist es eine eindimensionale Linie in einer zweidimensionalen Ebene; also z.B. ein Funktionsgraph oder eine sog. Kurve. Kurven sind in diesem Zusammenhang sehr interessant als Teilmenge eines Vektorraums, die durch eine Abbildung von einem reellen Intervall in den Vektorraum als sog. “parametrisierte” Kurve dargestellt werden kann. Das “Umparametrisieren” ist dann eine Äquivalenzrelation zwischen parametrisierten Kurven. Eine “Kurve” kann dann als Äquivalenzklasse solcher parametrisierten Kurven verstanden werden. Als Repräsentant einer Äquivalenzklasse nimmt man dann gerne eine nach Bogenlänge parametrisierte Kurve.
Wenn wir uns mit Kurven beschäftigen und speziell dann mit der Länge einer Kurve oder der Krümmung von Kurven, haben wir es mit Differentialgeometrie zu tun.
Dazu gibt es eine Reihe von sehr schönen Youtube-Videos:
Wenn das betrachtete Objekt ein Funktionsgraph von beispielsweise y = f(x) in der Ebene ist, können wir die Krümmung leicht berechnen:
Für eine zweimal differenzierbare Funktion y = f(x) ergibt sich der Krümmungsradius an einem Punkt x zu:
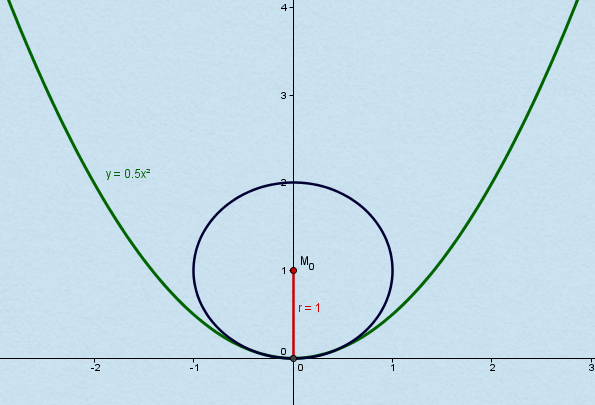
\( \Large r(x) = \left\vert \frac{(1+(f^\prime(x))^2)^\frac{3}{2}}{f^{\prime\prime}(x)} \right\vert \)Als Beispiel nehmen wir mal eine Parabel f(x) = 0,5 * x2
Dazu haben wir die Ableitungen:
f‘(x) = x
f“(x) = 1
Der Krümmungsradius beispielsweise am Punkt x0 = 0 beträgt dann laut obiger Formel:
Und zur Probe nehmen wir noch x=1:
\( \Large r(1) = \frac{(1+1^2)^{\frac{3}{2}}}{1} = 2^\frac{3}{2} = 2 \sqrt{2} \)Dieses Beispiel habe ich entnommen aus https://www.ingenieurkurse.de/hoehere-mathematik-analysis-gewoehnliche-differentialgleichungen/kurveneigenschaften-im-ebenen-raum/kruemmung/kruemmungsradius.html
Es wird grafisch veranschaulicht durch:
Wenn das betrachtete Objekt eine “richtige” Kurve in der Ebene ist, wird die Krümmung anders berechnet.
Als “richtige” Kurve (in der Ebene) betrachten wir von der obigen Parabel das Kurvenstück von x=-1 bis x=1. Als Parametrisierte Kurve, wobei der Parameter t auch von -1 bis 1 laufen möge, (was wir uns z.B. als Zeit vorstellen könnten) sieht das dann so aus:
\( \Large \alpha(t) = \left( \begin{array}{c} t \\\ \frac{1}{2}t^2 \end{array}\right) \\\ \)Um die Krümmung zu brechnen ermitteln wir zuerst:
\( \Large \alpha^\prime(t) = \left( \begin{array}{c} 1 \\\ t \end{array}\right) \)womit dann:
\( \Large ||\alpha^\prime(t)||^2 = 1 + t^2 \\\ \)und mit:
\( \Large \alpha^{\prime\prime}(t) = \left( \begin{array}{c} 0 \\\ 1 \end{array}\right) \)ergibt sich:
\( \Large det(\alpha^\prime(t), \alpha^{\prime\prime}(t)) = 1 \\\ \)und damit ergibt sich dann die Krümmung zu:
\( \Large \kappa_\alpha(t) = \frac{1}{(1 + t^2 )^\frac{3}{2}} \)Bei t=0 ist dann die Krümmung:
\( \Large \kappa_\alpha(0) = 1 \\\ \)und zur Probe nehmen wir noch t=1:
\( \Large \kappa_\alpha(1) = \frac{1}{2 \sqrt{2}} \\\ \)Weil t=x ist, stimmt das mit den Berechnungen des Krümmungsradius (s.o. Schritt 1) exakt überein.
Analog können wir uns gekrümmte Flächen im Raum vorstellen. Hier kann allerdings der Krümmungsradius in unterschiedlichen Richtungen unterschiedlich sein. Inetwa so die wir das von einem Gradienten kennen.
Auch in diesem Fall stellen wir uns das ganz klassisch geometrisch vor als Krümmung in eine weitere Dimension.
In der Allgemenen Relativitätstheorie spricht man auch von “Krümmung” z.B. Krümmung des Raumes oder Krümmung der Raumzeit.
Hier basiert die “Krümmung” nicht auf einer zusätzlichen Dimension, sondern auf einer speziellen Metrik in ein und demselben Raum. Unter “Metrik” versteht man ja eine Vorschrift, die zwei Punkten in dem betreffenden Raum einen Abstand zuordnet. So eine Metrik definiert dann auch automatische die Längen von Linien…
Die Linie, die die kürzeste Verbindung zwischen zwei Punkten bildet, nennt man Geodät oder auch Geodätische LInie. Auf der Erdoberfläche kennen wir das z.B. bei der Seefahrt oder Luftfahrt wenn wir beispielsweise die Flugroute von London nach Los Angeles betrachten:
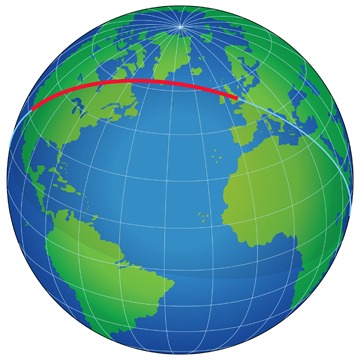
Das Licht läuft immer auf einer Geodäte, nimmt also die kürzeste Verbindung. Das kann “gekrümmt” aussehen…
Für eine solche Krümmung benötigen wir aber nicht zwingend eine zusätzliche Dimension. Die Krümmung kann auch “in sich” durch andere Abstandsgesetze (= Metriken) bewirkt werden.
Siehe Schwarzschild-Metrik
Gehört zu: Mathematik
Siehe auch: Python
Öfters habe ich schon Vorlesungen auf dem Youtube-Kanal von Prof. Dr. Weitz von der Hamburger Hochschule für Angewandte Wissenschaften (“HAW” – früher: Fachhochschule Berliner Tor) gehört.
Er arbeitet da mit Computer-Software wie:
und anderen.
Herr Weitz unterscheidet sog. Computer Algebra Systeme (abgekürzt CAS) von Numerischen Systemen…
Als Programmiersprache kommt man wohl an JavaScript nicht vorbei, das sich in den letzten Jahren enorm weiterentwickelt hat: z.B. https://eloquentjavascript.net/Eloquent_JavaScript.pdf
Gehört zu: Mathematik
Siehe auch: Quantenmechanik, Von Pytharoras bis Einstein, Schrödinger-Gleichung
Benutzt: WordPress-Plugin Latex
Stand: 29.7.2022
Ausgangspunkt ist die berühmte imaginäre Einheit: i2 = -1
Eine komplexe Zahl schreibt man gerne als Realteil und Imaginärteil:
z = x + i*y x = Re(z) und y = Im(z)
Wobei x und y reelle Zahlen sind.
Mit den Komplexen Zahlen kann man auch die vier Grundrechnungsarten, so wie wir sie von den “normalen” d.h. reellen Zahlen her kennen, ausführen – Die komplexen Zahlen bilden, mathematisch gesagt, einen “Körper”.
Zu jeder Komplexen Zahl gibt es die “komplex konjugierte“, die mit gern mit einem Sternchen als Superskript schreibt:
zur komplexen Zahl: z = x + i*y
ist die konjugierte: z* = x – i*y
Manchmal schreibt man die komplex konjugierte auch mit einem Strich über der Zahl. Also:
\( \overline{x + y \cdot i} = x – y \cdot i \)
Jede Komplexe Zahl hat auch einen “Betrag” (kann man sich als Länge vorstellen):
|z|2 = x2 + y2
Interessanterweise ist der Betrag (Länge) einer Komplexen Zahl auch:
|z|2 = z z*
Die Reellen Zahlen konnte ich mir ja durch die sog. Zahlengerade gut veranschaulichen. Die Komplexen Zahlen würde ich mir dann durch die Punkte in einer Ebene veranschaulichen.
Wenn komplex Zahlen einfach als Punkte in der Ebene verstanden werden können, kann ich sie anstelle von kartesischen Koordinaten, alternativ auch in durch sog. Polarkoordinaten darstellen; d.h. durch die Entfernung vom Nullpunkt r und den Winkel mit der reellen Achse φ.
Für eine Komplexe Zahl z = x + i*y gilt:
r² = x² + y²
tan φ = x/y
\(\displaystyle \tan{ \phi} = \frac{x}{y} \)Die Eulerschen Formel ist:
\(\Large e^{i \cdot \phi} = \cos \phi+i \cdot \sin \phi \\\)Damit können wir jede komplexe Zahl auch in sog. Exponential-Darstellung schreiben:
\(\Large z ={r} \cdot e^{i \cdot \phi} \\ \)Das funktioniert so gut, weil die Multiplikation von Potenzen der Addition der Exponenten entspricht und das mit den Summenformeln der Trigonometrie übereinstimmt.
Den Winkel φ nennt man auch “die Phase”.
Wenn die Komplexen Zahlen den Betrag 1 haben, also auf dem Einheitskreis liegen, hat man:
\( e^{i \phi} = cos{\phi} + i sin{\phi} \)und man spricht von einer “reinen Phase”.
In der Quantenmechanik wird diese Exponentialdarstellung gerne benutzt, u.a. weil man damit die Multiplikation komplexer Zahlen sehr anschaulich darstellen kann:
\(\Large z_1 \cdot z_2 = {r_1 \cdot r_2} \cdot e^{i \cdot (\phi_1 + \phi_2)} \\ \)Sie auch Youtube-Video:
Die Zahl e wurde von Leonhard Euler (1707-1783) als Grenzwert der folgenden unendlichen Reihe definiert:
\(\displaystyle e = 1 + \frac{1}{1} + \frac{1}{1 \cdot 2} + \frac{1}{1 \cdot 2 \cdot 3} + \frac{1}{1 \cdot 2 \cdot 3 \cdot 4} + … \)Oder:
\(\displaystyle e = \sum_{n=0}^{\infty} \frac{1}{n!} \)Potenzen zur Basis e bilden die Exponentialfunktion, auch e-Funktion genannt:
f(x) = ex
Die Ableitung (Differentialquotient) der e-Funktion ist wiederum die e-Funktion:
f'(x) = ex
Damit ergibt sich als Taylorsche Reihenentwicklung um den Entwicklungspunkt x0 = 0
\(\displaystyle f(x) = 1 + x + \frac{x^2}{2!} + \frac{x^3}{3!} + \frac{x^4}{4!} + … + \frac{x^n}{n!} + … \)Allgemein wäre die Taylor-Reihe ja:
\( \displaystyle T_\infty(x;x_0) = \sum_{k=0}^{\infty} \frac{f^(k)(x_0)}{k!} (x-x_0)^k \)Da der Funktionswert und alle Ableitungen der e-Funktion an der Stelle x0 = 0 sämtlich 1 sind, vereinfacht sich die Darstellung wie oben gezeigt.
Gehört zu: Mathematik
Siehe auch: Quantenmechanik, Vektorräume, Lineare Algebra, Koordinatensysteme, Metrik-Tensor, Kontravariante Ableitung
Benutzt: WordPress-Plugin Latex
Stand: 26.10.2021
Eine der Voraussetzungen zum Verständnis vieler Dinge (z.B. in der Allgemeinen Relativitätstheorie und der Quantenmechanik) sind sog. Tensoren.
Der Begriff “Tensor” wurde im 19. Jahrhundert relativ unsystematisch bei verschiedenen physikalischen Berechnungen eingeführt.
Darüber gibt es schöne Youtube-Videos von “eigenchris”: https://youtu.be/sdCmW5N1LW4
Als Vorbereitung dazu habe ich zuerst mal etwas zu Vektorräumen zusammengestellt.
Wir hatten ja im Artikel über Vektorräume schon gesehen, dass Vektoren Objekte sind, die unabhängig von Koordinatensystemen exsistieren und auch gegenüber einem Wechsel von Koordinatensystemen “invariant” sind. Nur die Komponenten bzw. Koordinaten der Vektoren verändern sich dann, nicht aber die Vektoren selber.
Invarianz bedeutet allgemein gesagt, dass ein und dasselbe Objekt verschieden beschrieben (“repräsentiert”) werden kann von verschiedenen Standpunkten (Koordinatensystemen) aus.
Unsere Vektorkomponenten beruhen immer auf einer Menge von sog. Basisvektoren.
Wie verhalten sich dann Vektoren und ihre Komponenten bei einem Wechsel der Basisvektoren?
Im Gegensatz zum invarianten Vektor selbst, verändern sich seine Komponenten bei Änderung der Vektorbasis.
Wir sahen, dass wenn sich die Längen der Basisvektoren verlängern, sich die Komponenten von Vektoren verkleinern. Deshalb hatten wir diese Vektoren “kontravariant” genannt.
So ein kontravarianter Vektor ist ein erstes Beispiel für einen Tensor. Ein zweites Beispiel für einen Tensor sind die sog. Co-Vektoren…
Allgemein gesagt bedeutet Kontravarianz, dass wenn ein Ding größer wird, ein anderes Ding kleiner wird. Kovarianz dagegen bedeutet, dass die Veränderungen in die gleiche Richtung gehen.
Im Gegensatz zu den “herkömmlichen” kontravarianten Vektoren, die wir als Spalte schreiben, schreiben wir Co-Vektoren als Zeilen.
Dazu hat “eigenchris” ein schönes Youtube-Video gemacht: https://youtu.be/LNoQ_Q5JQMY
In der Sichtweise von Koordinaten macht ein Co-Vektor also folgendes:
\( \Large \left[ \begin{matrix} a & b & c \end{matrix} \right] \cdot \left[ \begin{array}{r} x \\\ y \\\ z \end{array} \right] = ax+by+cz \)Abstrakt formuliert bildet ein Co-Vektor also Vektoren auf Skalare ab.
Generell soll ein Tensor ja invariant bei einer Koordinatentransformation sein.
Lediglich die “Darstellung” eines Tensors erfolgt mit Komponenten (Koordinaten).
Uns interessieren hier in erster Linie sog. Rank 2 Tensoren. Solche Rank 2 Tensoren können immer als “normale” Matrix mit Zeilen und Spalten dargestellt werden (Zeilen und Spalten -> Rank 2). So ein Rank 2 Tensor kann aber auch ganz einfach in sog. Index-Schreibweise dargestellt werden z.B. Tij oder g μν (Anzahl Indices = Rank).
xyz